CUDA Memory Model


CUDA 프로그램은 같은 일을 하더라도 구현 방식(알고리즘)에 따라 천차만별의 성능을 보인다.
그 중 Memory Model를 모르면 정말 프로그램이 한참 느려진다.
CUDA Memory Model
이를 위해 가장 먼저 알아야 하는 것이 memory model 이다.
CUDA 에는 여러가지 사용할 수 있는 여러가지 메모리가 있다.
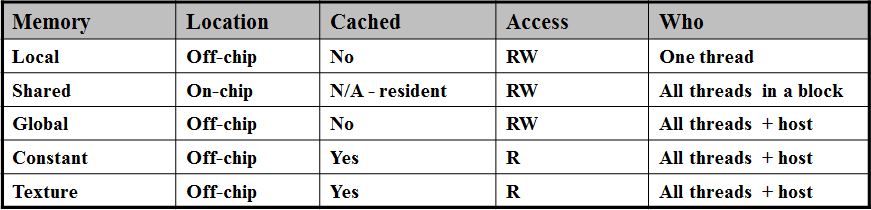
가장 중요한 것은 global memory 와 shared memory.
참고로, 위의 표에는 constant memory 와 texture memory 가 off-chip에 있다고 되어있지만 옛날꺼는 그렇고 요즘꺼는 on-chip 에 있다. - architecture 별 whitepaper 참조에서 확인해 볼 것)
Shared Memory
Shared Memory 는 CUDA 에서 제공하는 scratchpad memory로 프로그래머가 직접 데이터를 올려둘 수 있는 공간이다.
Shared memory 는 한 thread block 내의 thread 들 끼리 공유하는 영역이라 통신이 가능하고, SM (Streaming Multiprocessor) 안에 있기 때문에 빠르다.
실제로 L1 cache 와 물리적으로 같은 위치(거리?)에 위치해 있어서, 읽는 데에 10 cycle 내로 걸린다. (cache 에서 miss가 난 경우 보통 memory 까지 가면 수백 cycle이 걸린다고 한다.)
사용 방법
사용방법은 아주 간단하다.
CUDA 커널 내에 아래와 같이 변수가 선언되어있다면,
float data[64][64]
다음과 같이 _shared_ 를 붙여주기만 하면 된다.
__shared__ float data[64][64]
주의할 점은 thread block 밖의 thread 끼리는 변수를 공유 할 수 없다.
그리고, 물리적인 크기가 Fermi architecture (ex. GTX480) 기준으로 48KB를 넘어갈 수 없다.
속도는 무진장 빨라진다.
내가 직접 실험해본 바에 의하면 Neural Net 코드를 돌려보았는데, 저것만으로 속도가 2배가 차이가 난다.