어떤 Deep Learning Library를 선택해야하나요?


**Deep Learning(딥러닝)**이라는 기술이 최근 거의 모든 기계학습류 문제의 해결책으로 떠오르고있다. "이 기술을 무엇으로 구현해서 사용하는 것이 가장 효율적인가" 라는 질문이 아주 흔하다. 대부분은 딥러닝을 시작하는 김에 더 빠르고, 더 메모리가 효율적인 것이고, 더 쉬운 라이브러리를 사용하고 싶은 욕심일 것이다.(나도 그랬으니까)
만약 누군가 Convlutional Neural Network(CNN) 등을 Foward, Backward pass등을 전부다 고려하면서 직접 구현한다면 연구/개발의 최고 고수이고 모두의 Wannabe일 것이다. 하지만 CNN 구현의 내막에는 GPU/CPU, Data processing, Linux, C/C++ 등 다양한 고급 지식을 필요로하니 이미 좋은 라이브러리가 있으면 가져다 쓰는게 더 좋다. 하지만 겉 햝기식으로는 역시 수 백명이 공헌하고 있는 오픈소스 라이브러리의 디테일하고 강력함을 알 수 없다. 그래서 라이브러리가 오픈소스지만 방대한 양의 코드를 직접 읽어가면서 기본적인 작동원리를 반드시 알야한다.
하지만 나처럼 하고싶은데 어디서 시작할지도 모르는 사람들은, 뭘 봐야되는지 조차 모른채 파편적인 정보를 모아가면서 이게 좋다더라, 저게 좋다더라 맴돌기 일쑤이다. 그래서 누구나 그렇듯이 어떤 라이브러리로 시작할지 고민하고, 시작도 전에 두려움이 크다. 나는 아직도 그런 면에서 고민하고 있고, 지식의 나눔(블로그, 모두의연구소, 페이스북 커뮤니티, AI Korea, reddit, 연구실 선배 등)에서 큰 도움을 받았듯이 내가 아는 것, 내가 배우는 것 등을 공유해보려한다. 그래서 누구나의 시작인 **"딥러닝 라이브러리 선택하기"**에 대해서 얘기해보려한다.
만약 모든 면모에서 제일 완벽한 라이브러리가 있으면 그 하나만 살아남는 것은 당연하다. 그렇지만 사용하지 않아 사라지지않고, 오히려 새로운 딥러닝 라이브러리들(CNTK, veles)이 여기저기 공개되는 이유는 아직도 기계학습에서 우리가 풀려는 문제들의 다양성과 그것을 풀기에 더 적합한 라이브러리가 서로 경쟁하기 때문이 아닐까? 못은 망치질하고 나무는 도끼질하는 것처럼 어떤 라이브러리가 더 좋다가 아니라 어떨때 더 좋은지가 옳은 질문인듯하다.
마침 유명한 스탠포드의 CS231n: Convolutional Neural Networks for Visual Recognition 강의에서 딥러닝 라이브러리에 대한 강의가 나왔고 다시 참고하기위해 나름 요약해놓은 것을 옮긴다.
나의 이해를 기반한 요약이라 친절하지도 않다. 최소한 강의노트와 비교해서 보던가 직접 영상을 보는 것이 더 도움이 될 것이다. 이 글에서는 가장 널리 쓰이는 Caffe, Torch, Theano, TensorFlow를 다루었다. AI Korea에서도 라이브러리 설문을 했었고 그리고 간략한 소개들과 함께 블로그 포스트를 올린 것도 참고하자.
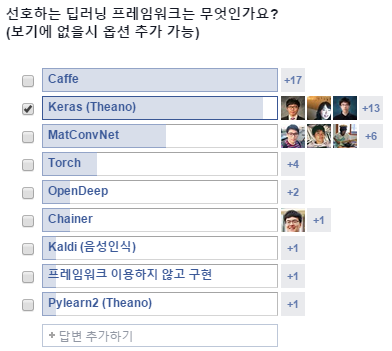
당시에는 TensorFlow가 없었다.
강의영상 (2016.2.22)
[course note](http://vision.stanford.edu/teaching/cs231n/slides/winter1516_lecture12.pdf)Caffe
내가 처음 시작한 프레임워크. 잘 모를 때는 설치하는 것 조차 너무나도 고생했다. CUDA 설치부터, cuDNN 버전 맞추기 등에서 너무나도 시행착오를 많이하고 덕분에 Linux 실력도 엄청 올랐다. 하지만 새로운 layer가 필요하게되면서 복잡한 C/C++ 코드를 보면서 내가 필요한 기능을 구현할때는 만능은 아니란 것을 알게되었다. 잔뜩 고생하고났던 Caffe 설치는 나만 그랬던 게 아닌듯, 모두의연구소 기술블로그에서 자세히 설명되어있다.
Caffe는 prototxt라는 뉴럴넷 아키텍쳐 구조를 google이 개발한 json 비슷한 포맷으로 작성함. 내가 풀고자하는 solver라는 것도 미리 작성함. 그걸 base로 training함.
prototxt작성하는게 생각보다 빡쎔. lr같은것 전부다 내가 써줘야되고... 예를 들어 conv layer들 learning rate를 freezing 해주고 싶으면 prototxt에서 일일히 바꿔줘야한다. 뭔가 coding하듯 변수하나만 바꿔주는 그런 게 없는게 아쉽다. Python wrapper는 생각보다 잘 되어있지만 documentation이 많이 친절하지 않아서 $CAFFE_ROOT/examples/pycaffe에 있는 code, $CAFFE_ROOT/python도 전부 읽어야했다. 또 막상 쓰긴 어려워서 Fast-RCNN 같이 다른 사람이 PyCaffe를 이용한 code를 참고하고 모방하면서 공부했다. iPython을 통한 개발이 특히 편했다.
장점:
- 빠르다. 코드 작성 없이도 실행시킬수 있다.
- Good for feedforward networks
- Good for finetuning existing networks
- Train models without writing any code!
- Python interface is pretty useful!
단점:
- Need to write C++ / CUDA for new GPU layers
- Not good for recurrent networks
- Cumbersome for big networks (GoogLeNet, ResNet)
그냥 feature 뽑거나, classification finetuning에서는 매우 편하다. 하지만 새로운 loss layer가 필요하게 되거나, 그 외의 특이한 아키텍쳐 구조로 설계하려면 방대한 C/C++ code도 이해해야한다.
Torch
특징:
- Lua를 사용하며 이는 Javascript 비슷한 script 언어.
- Python보다 빠름. Just in time compilation 때문에.
- Luarocks로 Python의 pip처럼 lua package를 설치
- Lua 15분만에 배우기
First-class functions. (Programming Language에 나오는 지식이지만) - 함수를 parameter로 전달
- 변수에 할당
- 리턴값으로 함수를 받음
- 런타임에 함수 생성
- 위에 것들이 가능 http://rapapa.net/?p=2890.
- Facebook, DeepMind, Twitter에서 이용 (믿음직한)
-
- Twitter, Facebook 등이 유용한 package 배포
- Numpy처럼 다룬다.
- GPU 이용한 코딩이 매우 쉬움 (Caffe에 비교해서)
- 모듈안에 내 코드를 만들어서 사용가능.
- prototxt로 네트워크 구조를 짜는게 아니라, nngraph등으로 lua code에서 텐서와 텐서를 연결하는 node 등을 만들어서 구현
Torch: Typical Workflow
Step 1: Preprocess data; usually use a Python script to dump data to HDF5
Step 2: Train a model in Lua / Torch; read from HDF5 datafile, save trained model to disk
Step 3: Use trained model for something, often with an evaluation script
장점:
- Lots of modular pieces that are easy to combine
- Easy to write your own layer types and run on GPU
- Most of the library code is in Lua, easy to read
- Lots of pretrained models!
단점:
- Lua
- Less plug-and-play than Caffe
- You usually write your own training code
- Maybe more overhead, but give more flexibility
- Not great for RNNs
- multiple modules that share weights each other —> brittle, sublte bugs
Q:
Lua는 Python만큼 code를 효율적으로 짜는 것에 이점이 적나?
A:Python은 interpretered 언어라 4 loop이면 큰 memory allocation을 함.
Javascript처럼 빠른데 이 역시 JIT, compile code on the fly.
LuaJIT도 비슷한 메커니즘. compile into native code.
still 커스텀 vectorized code가 speed-up에 좋음.
내 생각: Lua라는 진입장벽이 있지만, 어렵지 않다고 생각하게 되었다. 오히려 구현상의 유연함에 나는 반드시 Torch를 해야하는 이유가 생겼다. 연구를 하면서 가져다만 쓰는게 아니라 내가 필요한 것을 구현해야하는 경우가 생기기 때문이다.
Theano
computation graph. Torch의 nngraph. 복잡한 모델 아키텍쳐를 붙이는데 편리함.
Keras, Lasgane 같은 더 high-level wrappers
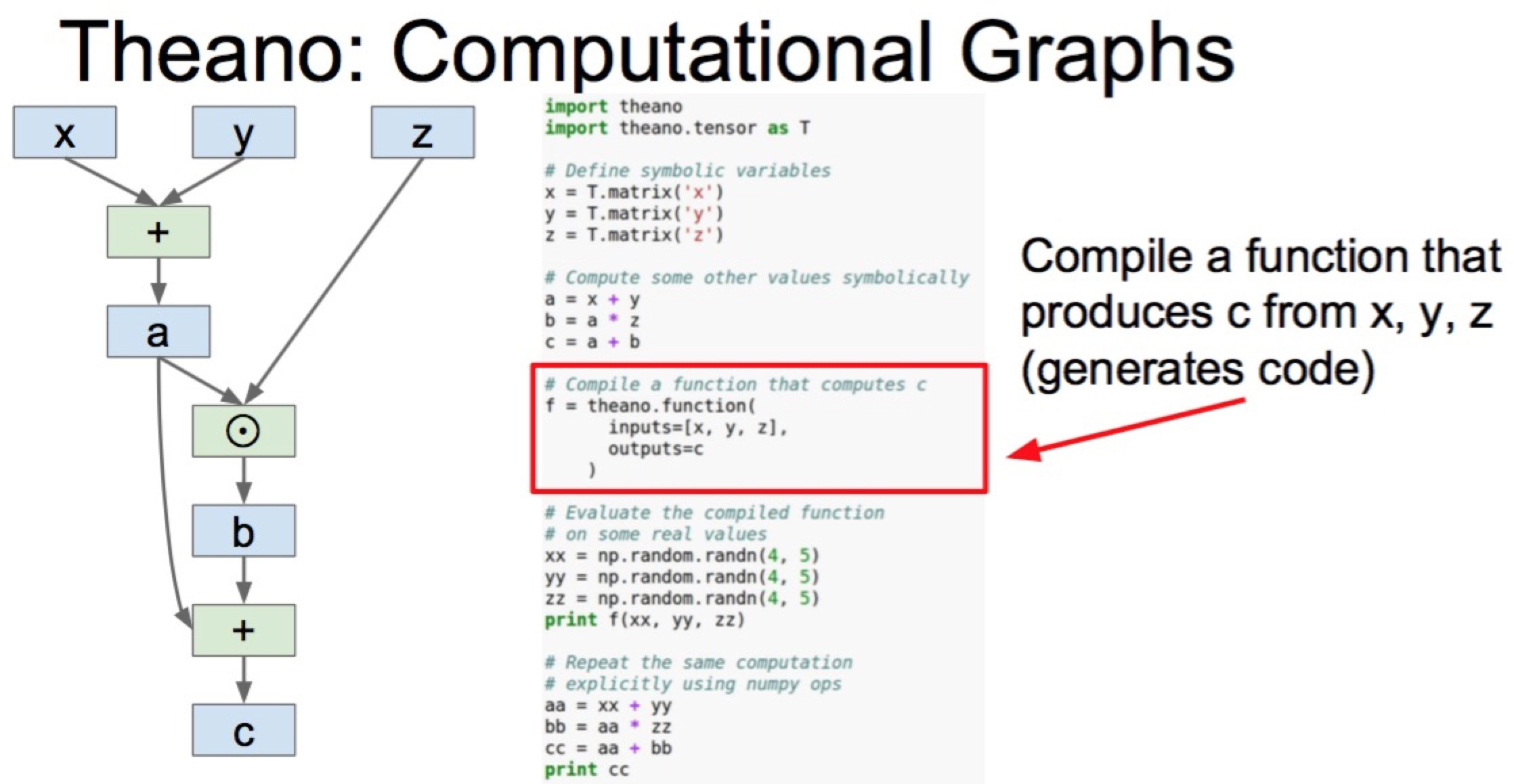
Compile a function 이 부분이 Theano의 큰 장점.
Symbolic variables들이 elements in computational graph가 됨.
Backend에서 그래프를 그려냄
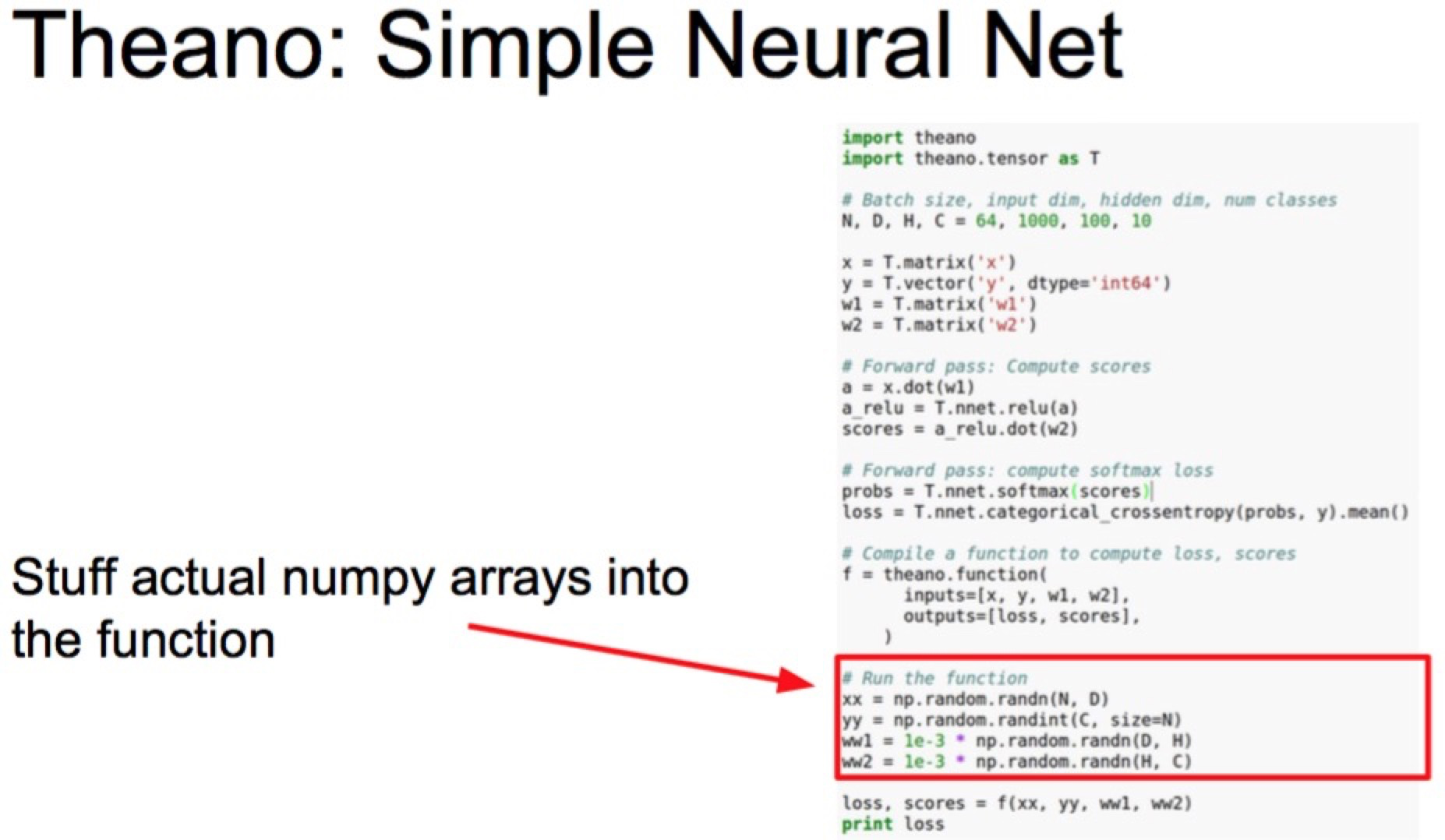
여기까지가 Forward pass고 Backward는 다음과 같음. Symbolic differentiation을 해낸다.
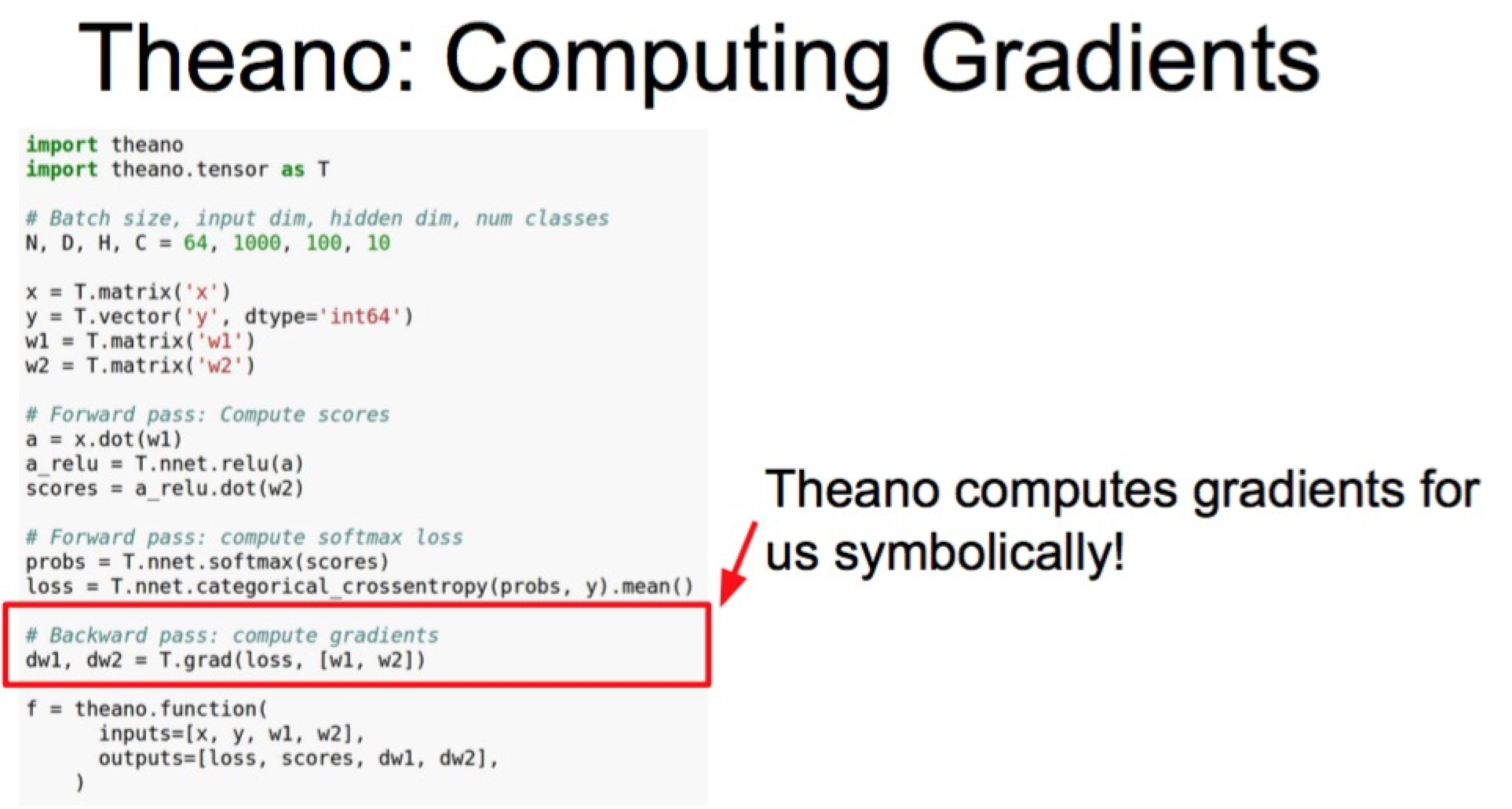
하지만 위 code는 GPU <-> CPU 통신이 bottleneck이 된다.
f function을 부를 때마다 gradient로 돌아와서 GPU에서 CPU로 복사하는 numpy operation. dw1, dw2를 계산해서 다시 넣고 하기 때문에.
그래서 우리 parameter들의 gradient update를 gpu에서 바로 하고 싶음.
이래서 theano에서는 shared variable이란 걸 사용함.
이제 weights를 input으로 사용하지않음. gradients말고 loss만 output으로 사용함.

Theano의 High level wrapper들.
- Lasagne : Higher level. Theano 처럼 f compile하고.
- Keras: 더 High level. TensorFlow도 지원함. 근데 너무 high해서 theano측에서 bug 일어나면 debugging 매우 힘듬. Crashes really bad. 우리가 쓴 code에서 error가 안나는 confusing error. Theano backend의 debugging이 너무 힘듬.
(+)장점, (-)단점
(+)Python + numpy
(+) Computational graph is nice abstraction
(+) RNNs fit nicely in computational graph
(-) Raw Theano is somewhat low-level
(+) High level wrappers (Keras, Lasagne) ease the pain
(-) Error messages can be unhelpful
(-) Large models can have long compile times
Neural Turing Machine 같은건 반시간도 걸린다고함.
(-) Much “fatter” than Torch; more magic
(-) Patchy support for pretrained models
하지만 Lasgane에서 pretrained model이 많음.
내 생각: 유일하게 Windows에서 돌아간다. 아무래도 Vision 연구와 NLP가 겹치게되고 또 앞으로 유망한건 RNN이니까 high-level인 Lasagne까지는 필요할 때만 다룬다면 좋지 않을까?
TensorFlow
새롭고 많은 사람들이 관심가지고 있는 library. Theano랑 많이 닮은(Computationa graph) Google이 공개한 라이브러리. 그래서 Keras가 support가능한듯.
전문 엔지니어들이 작정하고 처음부터 개발함. Academic research lab에서 개발한 것들은 … 대학원생이 유지보수함 ㅎ…(전체 웃음)
Torch도 원래 Academic project 그랬는데 이젠 Twitter, Facebook이 유지보수함.
TF는 ground up 부터 산업목적으로 개발됨, better code quality 일수도.
Theano의 matrix and vector in symbolic variable들이 TensorFlow에선 placeholders로.
creating input nodes.
update rule은 약간 Keras나 Lasagne같음. pre-buillt 된 SGD같은걸 사용. gradient를 내가 따로 관리해주지 않음.
Theano에선 f compile했고.
session run을 하고 어떤 값을 compute하고, 어떤값을 feed하는지 입력값으로 줌.
TensorBoard. Easily visualize what’s going in my model
loss_summary = tf.scalar_summary(‘loss’, loss)
w1_hist = tf.histogram_summary(‘w1’,w1)
w2_hist = tf.histogram_summary(‘w2’,w2)
를 추가해줌 코드에. 등등 이런 작업을 해줌. 궁금한 variable을 값을 disk에 dumping해줘서 볼수있음.
그래서 이런 정보를 실시간으로 TensorBoard라는 웹서버를 통해 streaming해줌.
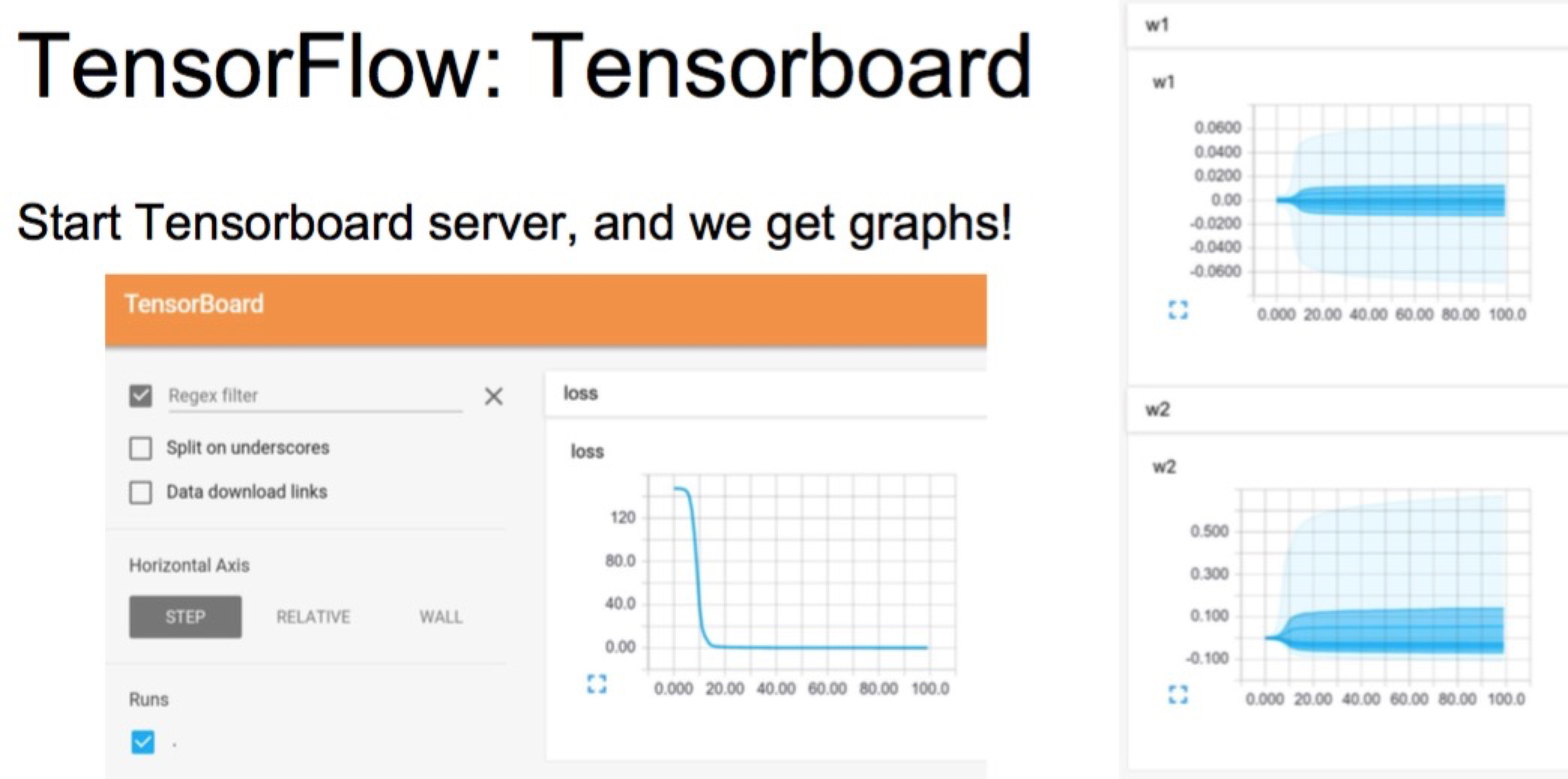
디버깅할 때 매우좋음.
강연자는 Torch등에서 손수 debugging을 위해 값들을 뱉 어내는 json을 구현해봤지만
TensorBoard가 다 해줌.
네트워크 생긴것도 visualize해줌. 원하는 scope를 지정해주면 이렇게 보여줌.
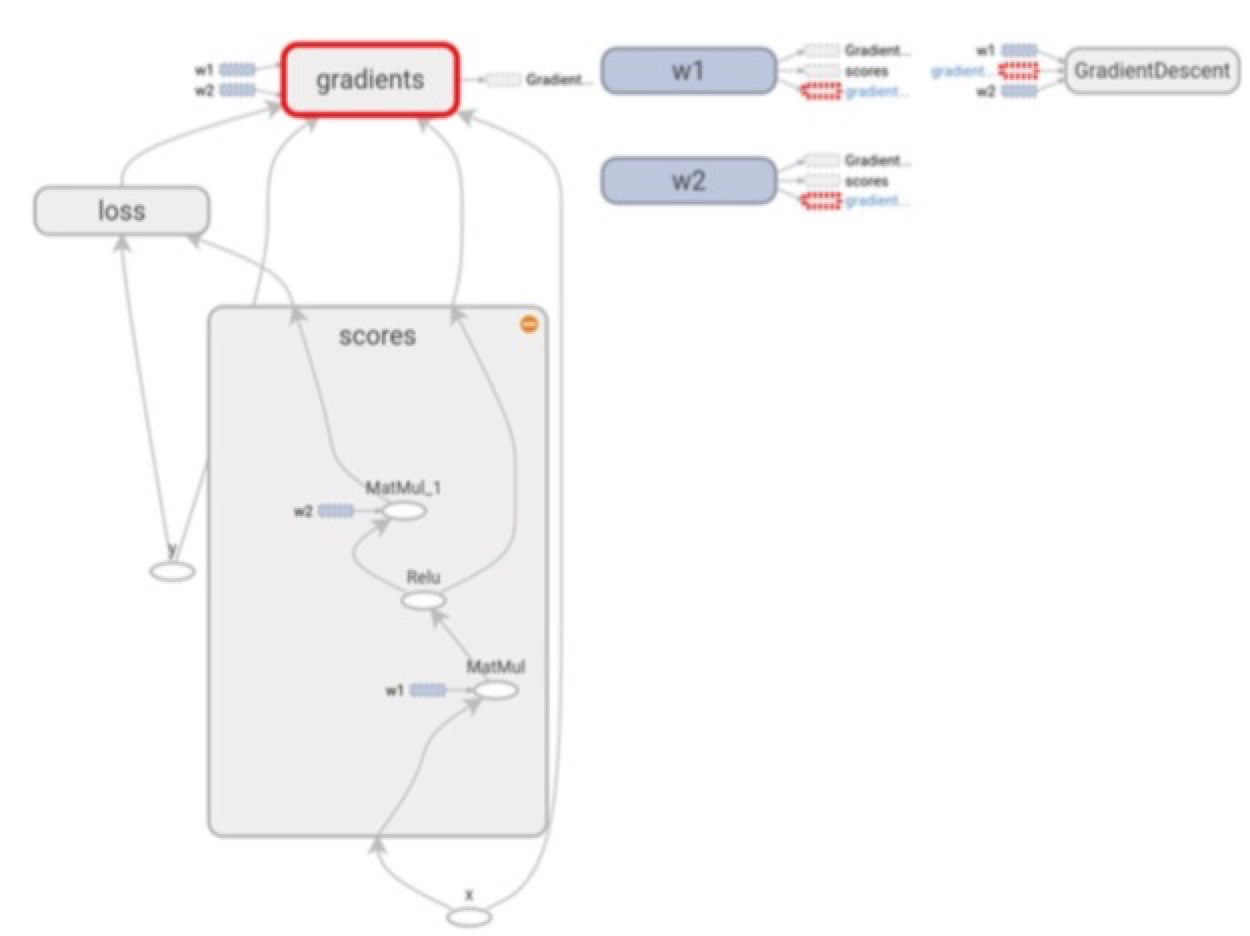
Multi-GPU
Data parallelism(Synchronous, asynchronous) 가능. minibatch 원하는 곳에 붙이고 등등.
Model parallelism. model을 GPU마다 할당 가능.
분산환경. 한 machine 말고, many machines. 아직은 오픈소스로 공개되지않음.
Pretrained model구하기 힘듬..
(+) Python + numpy
(+) Computational graph abstraction, like Theano; great for RNNs
(+) Much faster compile times than Theano
(+) Slightly more convenient than raw Theano?
(+) TensorBoard for visualization
(+) Data AND model parallelism; best of all frameworks
(+/-) Distributed models, but not open-source yet
(-) Slower than other frameworks right now
(-) Much “fatter” than Torch; more magic
(-) Not many pretrained models
하지만 코드 뒤져보기 어려워...
신박한, 빨리빨리 code 만들고 싶을때, 근데 computational graph abstraction이 잘 안되면 문제가 많음.
Torch는 imperative(긴급한) code를 forward pass / backward pass를 빨리 만들어 낼 수 있는데 custom layer. TF는 어렵나봄.
Q: 어떤게 윈도우를 지원하나요? (전체 웃음)
A: 미안, 몰라요, 알아서 하세요.
내 생각: 구글이 유지보수를 해주므로 최고의 프레임워크가 될 수 있지만, 내가 필요한 것을 구현하지 못한다면 의미가 있을까? 텐서보드같은 특징은 굉장하다. 계속 발전할 library이며 RNN을 하게될때 필요할 것 같다.
Use cases, Q&As
Extract AlexNet or VGG features?
Use Caffe!
Fine-tune AlexNet for new classes?
Use Caffe!
Image Captioning with fine-tuning?
-> Need pretrained models (Caffe, Torch, Lasagne)
-> Need RNNs (Torch or Lasagne)
-> Use Torch or Lasagna
Caffe에 RNN기능 구현한게 있지만, 여전히 다루기 어려움.
Segmentation? (Classify every pixel)
-> Need pretrained model (Caffe, Torch, Lasagna)
-> Need funny loss function
-> If loss function exists in Caffe: Use Caffe
-> If you want to write your own loss: Use Torch
Object Detection?
-> Need pretrained model (Torch, Caffe, Lasagne)
-> Need lots of custom imperative code (NOT Lasagne)
-> Use Caffe + Python or Torch
Lasagne로 computational graph를 그리는건 매우 어려워 보임.
Language modeling with new RNN structure?
-> Need easy recurrent nets (NOT Caffe, Torch)
-> No need for pretrained models
-> Use Theano or TensorFlow
Implement BatchNorm?
-> Don’t want to derive gradient? Theano or TensorFlow
-> Implement efficient backward pass? Use Torch
결론적으로 유연하게 뜯어고치면서, 내가 원하는 새로운 layer을 정의하고 loss function도 설계하려면 Torch를 사용해야한다.
Recommendations.
Feature extraction / finetuning existing models: Use Caffe
Complex uses of pretrained models: Use Lasagne or Torch
Write your own layers: Use Torch
Crazy RNNs: Use Theano or Tensorflow
Huge model, need model parallelism(그리고 구글 내부 code base에 접근가능하다면): Use TensorFlow
More Q&As
Q: 제일 빠른건?
A: 여기에 없어요, Neon이라고 Nervana에서 만든건데, 아주 미친놈들임.
CUDA가 맘에 안들어서 custom assembler on NVidia Hardware.
하드웨어 reverse engineering하고 새로 kernel, assembly 작성함. 위 4개 라이브러리에서는 cuDNN 쓰면 속도 비슷하지만, TF가 조금 느리긴함. 하지만 TF가 느릴 이유는 없음, 고쳐질거라고 생각함.
Q: Graphics in Torch?
A: iTorch notebook 사용가능. simple graphing 가능한데, 나는 torch model돌리고 dump data into JSON HDF5한다음 python으로 visualize.
마무리
결국엔 각자의 다 장점이 있다. 이 중에 무엇을 선택할까? 라는 질문보다는, 내가 무슨 문제를 풀 것인지 고민해야한다. 그리고 무엇을 하든 빠르게 배우고 빠르게 구현하는 능력이 중요할 것 같다.