Weakly supervised Learning으로 Object localization하기

공유하고자하는 논문의 제목은
Learning Deep Features for Discriminative Localization
Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba
Computer Science and Artificial Intelligence Laboratory, MIT
논문의 데모는 "여기"서 쉽게 해볼 수 있다.
데모의 내용을 풀이하자면 먼저 처음엔 scene label로 태깅되어 있는 데이터로 Weakly supervised learning을 한 CNN을 학습시킨다. 그리고 아래 사진을 input으로 넣어준다면,

이 이미지가 분류되는 scene classs는 artstudio이며 이것이 어떻게 추론되었는지를 Class Activation Map으로 위 사진처럼 보여(visualize)준다.
"Class" Activation Map이란 이름의 의미는, 이 이미지가 만약에 Top-2 class인 artgallery라고 추론한 이유도 visualization이 가능하기 때문이다. 즉 Class마다 Activation map을 볼 수 있다.
결국 제목은 최대한 쉽게, image label로 object detection이 가능하다를 검증한 논문이다.
내가 NeuralArt에 관심을 가지면서 보았던 Understanding Deep Image Representations by Inverting Them , CVPR2015 같은 논문에서는 CNN에 encoding 된 visual information을 CNN을 통과시킨 feature map에서 inverting 시킴으로써 분석해본다. 예를들어서

각각 convolution layer[1]의 CNN feature map에서 원래 input image를 복원한다. 하지만 이건 CNN feature에 어떤 정보가 들어있는지를 보는 논문이었고, 지금 소개하는 논문은 어떤 feature map이 activation 되는지를 보여주는 것으로 정리할 수 있다.
논문의 결과를 간단히 옮기면
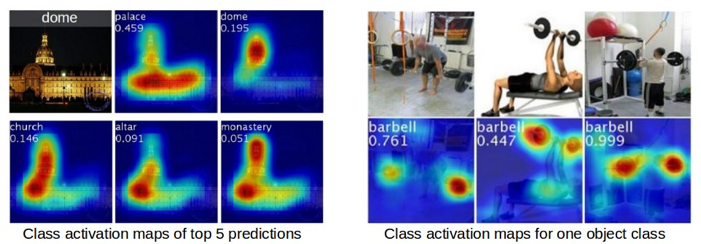
이렇게 되는데. 간단히 설명하자면, Dome이라고 태그되어 있는 이미지가 palace로 prediction 될 때의 Class Activiation Map (이제 CAM이라 줄여쓰겠다.), dome, church ... 등으로 prediction 될 때 각각 CAM을 보여준 것이다. 그리고 오른쪽 figure는 각 이미지들에서 babel에 대한 CAM등을 보여준 것이다.
논문의 Contribution은 먼저
- Weakly supervised object localization
- 이미지 label에 대해서만 training 되었다.
- 즉, object의 bounding box, segmentation 같은 건 전혀 학습데이터에 들어가지 않는다.
- 그럼에도 불구하고, 꽤나 준수한 object localization이 가능하다.
- CNN feature를 visualization했다. (internal representation of CNNs)
- 이것을 Class Activation Map(CAM)이라는 방법으로 Localization을 하였다.
- 어떤 output의 어떤 visual pattern에 의해 activated된 각각 unit들을 visualize
- 이것들이 복잡한 방법들로가 아니라, 간단한 idea로, 단 한번의 CNN forward pass로 localize, CAM이 가능하다.
Weakly Supervised Object Localization
첫 딥러닝에서의 approach는 양질의 labeling이 된 굉장히 많은 data를 통해 CNN을 학습시키는 것이다. 즉 Data-driven인 딥러닝은 결국 data 의존도가 매우 많은데, 실제로 세상에는 data가 많다고 쳐도 labeling이 되어 있지는 않다. labeling 자체가 수고가 많이드는 작업인데, 그냥 image가 어떤 object class다 라고 태깅하는 건 비교적 쉽지만, 그 물체가 어디에 있는지 bounding box, segmentation annotation을 만들어주는 건 굉장히 수고스럽다. 결국 ImageNet같은 좋은 data들이 있지만 더 구체적인 문제를 해결하려고하면 그에 대한 data가 없어 학습이 불가능할 수 있다. 방금 말한건 CNN의 Supervised learning에서의 문제라고 볼 수 있는데, 그렇다면 조금 약한 label로 더 구체적인 문제를 풀어 볼 수는 없을까? 즉 이를 Weakly supervised learning이라 하는데, object label로만 object localization을 해보자! 라는 것이 이 논문의 취지이다.
CNN feature는 우리가 몰랐던 representation이 무궁무진하다. ImageNet으로 training 된 model을 다른 domain 문제에서도 적용해서 이것저것 바꾸면서(tuning) 해결하려는 시도(예를 들어 object localization, segmentation, saliency prediction, NeuralArt)가 무수히 많았고 성공적이었다. CNN이 hierarchical model이라는 것의 장점과 deep해 질 수록 contextual meaning 들을 담아 내고 있는 것이 딥러닝 연구가 진행되면서 알아낸 공통적인 맥락이다. 이 CNN feature의 gram matrix를 계산해서 고흐 풍의 그림을 그려낸 것도 CNN feature의 representation 능력이 매우 뛰어남을 보여준다.
이 CNN의 장점을 이용하여 object class로 학습했음에도 불구하고 object localization이 가능하다는 것은 이미 밝혀진 내용이다.
Caffe-Net Surgery Tutorial, Is object localization for free? – Weakly-supervised learning with convolutional neural networks Oquab et al. CVPR2015 등을 참고.
CNN Architecture
CNN의 구조는 다음과 같다.
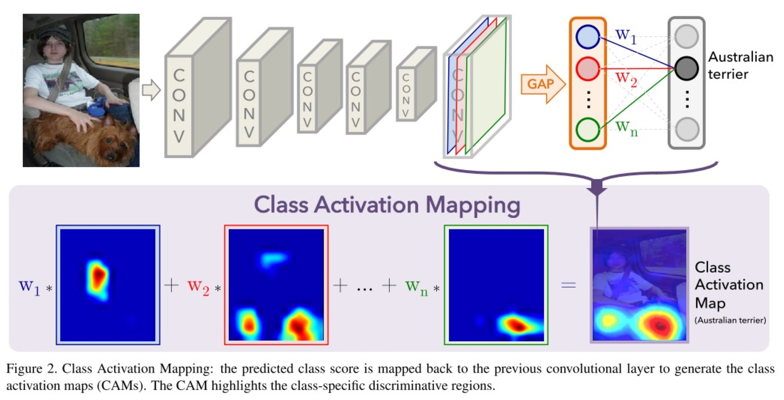
쉽게 말하면, Fully connected(FC) layer을 다 제거하고 마지막에 Global Average Pooling(GAP)을 하여 1x1x512 같은 vector로 mapping한다. 그리고 여기서 FC layer를 달아서 softmax로 classification을 학습시킨다. FCN을 지향하기 때문에 GoogLeNet의 성능이 제일 좋다.
GAP: 쉽게 설명해보자면, 우리가 CNN에서 주로 하던 pooling은 max-pooling이다. Pooling을 하는 이유는 CNN feature dimension을 줄여서 over fitting을 피하고자함이고, max-pooling을 하는 이유는 activation된 neuron을 더 잘 학습하고자함이다. (사실 실험적인 이유가 큰듯한데) 주로 2x2 max-pooling을 해서 HxWxC dimension을 H/2xW/2xC, 1/4배로 줄였는데, global pooling은 HxW pooling이란 의미이다. 즉 한 feature map (HxWxC)을 전부 pooling해서 한 neuron(1x1xC)으로 mapping 시킨다는 것.
따라서 각 feature map은 GAP을 통해 한 neuron이 된다. 그리고 이 neuron들에 적절한 weight를 준 FC layer을 학습시켜서 classification을 하게 되는데, 만약에 Australian terrier로 classification이 되면 그렇게 분류 시킨 FC의 weight를 고대로 각 feature map에 가중치를 주어서 CAM을 뽑아낸다.
이 내용은 CNN의 기본적 이해가 있다면 쉽게 이해가 될텐데, 자세한 설명은 논문을 읽는게 더 좋을 듯 하다.
GAP이 Global Max Pooling(GMP)보다 좋다고 주장하는 이유도 간략히 바로 옮기자면
Intuitive difference between GMP and GAP?
- GAP loss encourages identification on the extent of an object.
- GMP loss encourages it to identify just one discriminative part.
- GAP, average of a map maximized by finding all discriminative parts of object
if activations is all low, output of particular map reduces. - GMP, low scores for all image regions except the most discriminative part
do not impact the score when perform MAX
Object localization은 CAM에서 20% threshold를 주어 bounding box를 만들어낸다.
이렇게 ImageNet을 새로 처음부터 GAP을 붙여 training 시킨 모델로 다른 domain 문제에도 실험을 굉장히 많이했는데 몇개만 옮기자면
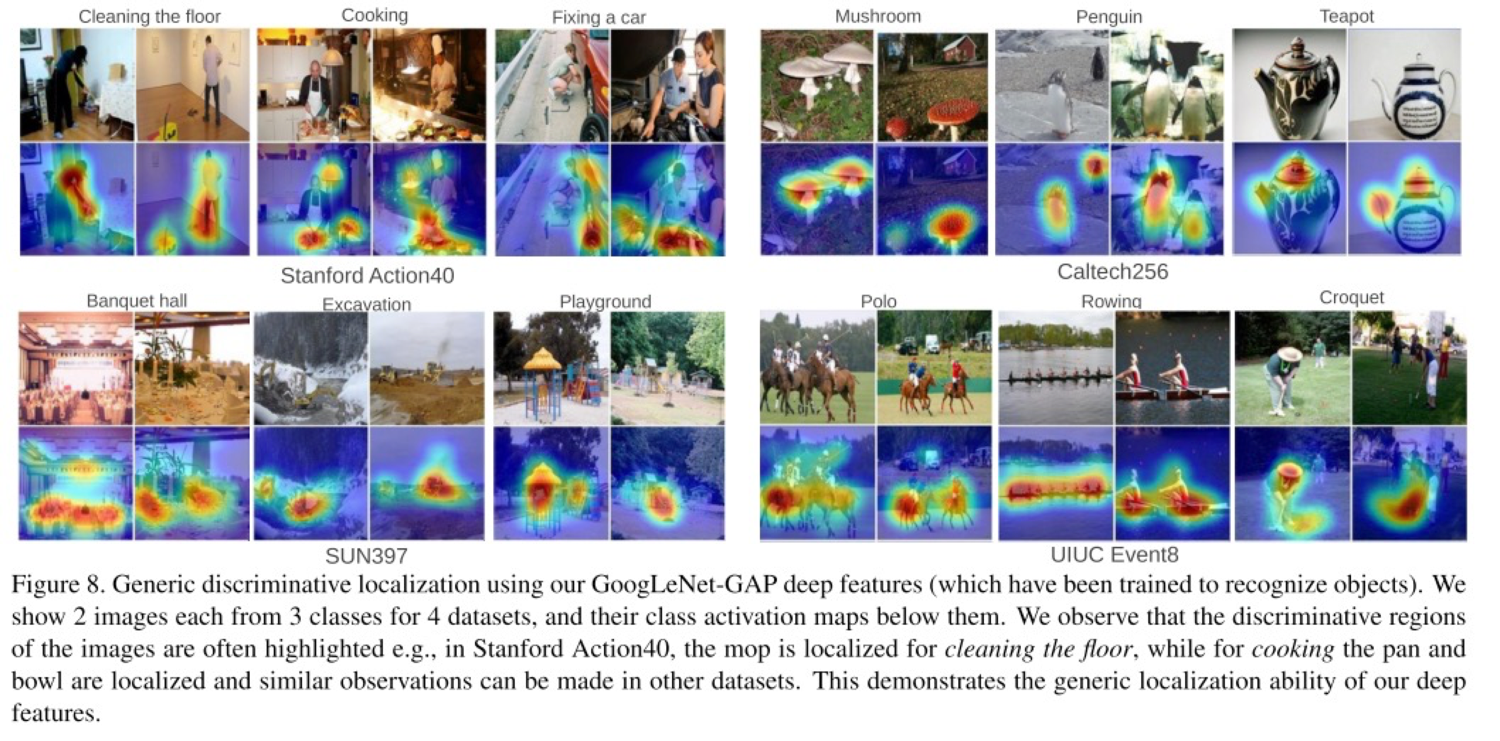
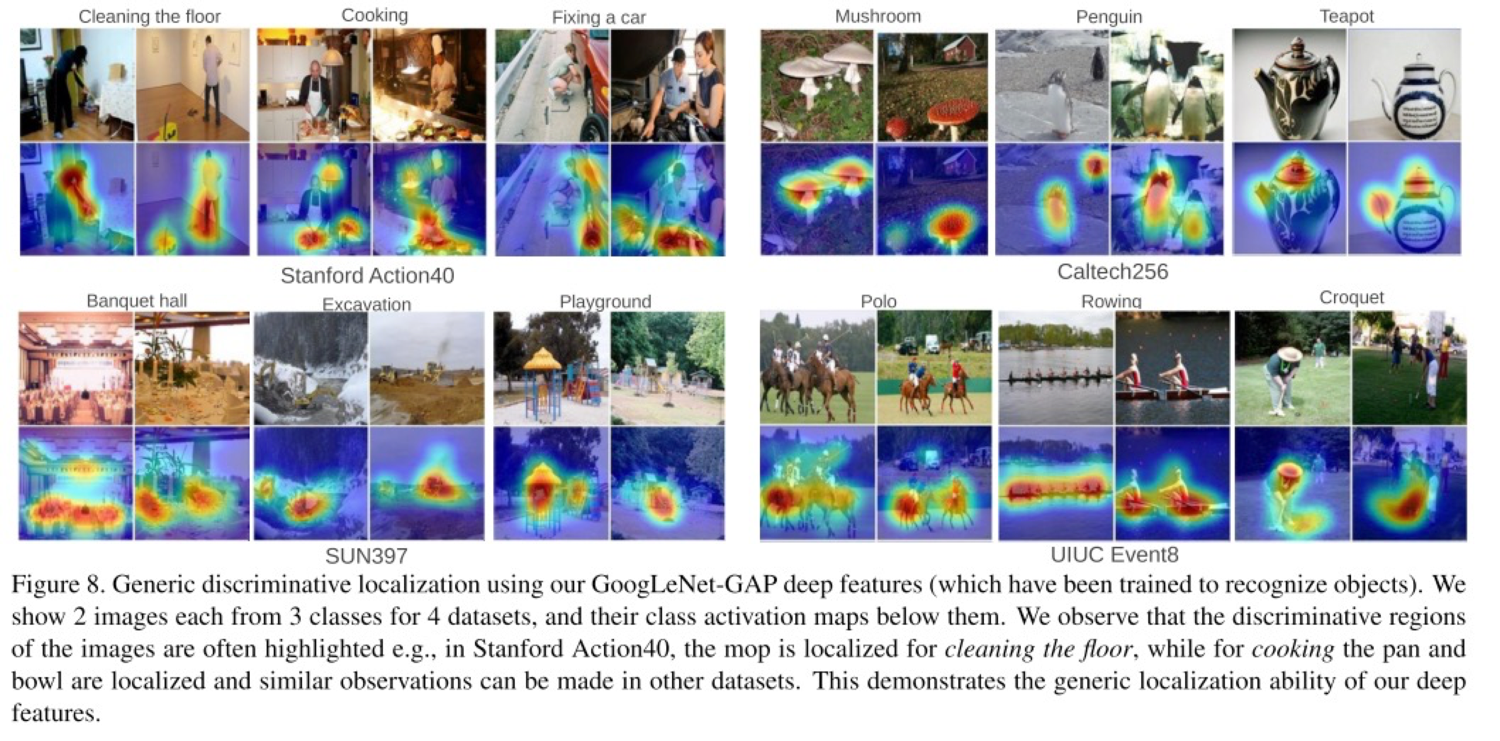
Action, Event 같이 한 object가 아닌 것도 visualization이 가능한데, 잘 보면 Cooking을 한다는 것은 사람이 주방기구를 사용하니까 그런 영역에 activation이 일어난다.
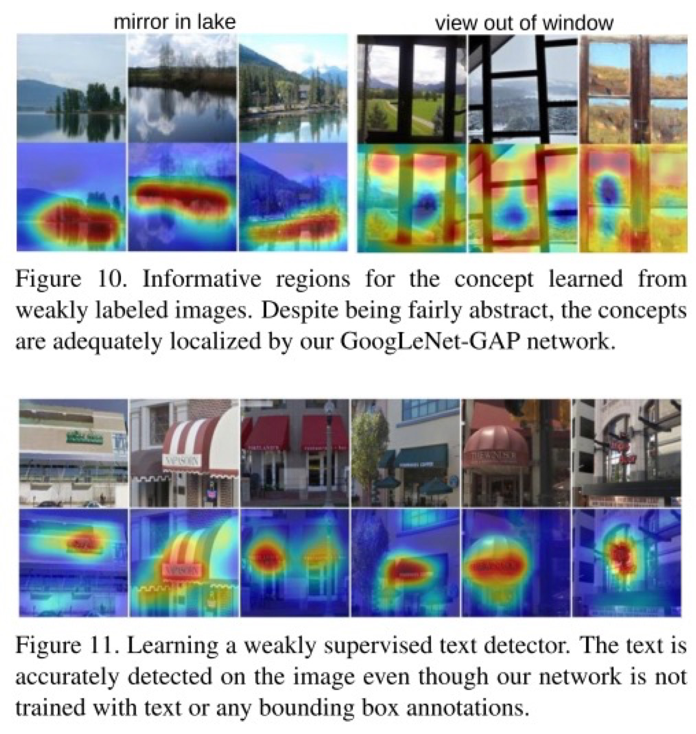
이미지에 concept이 tagging된 것들로 학습해서 mirror-in-lake가 어디 부분에서 activation이 되었는지 (물론 그 concept에 대한 위치 정보로 학습한 것이 아님), 그리고 구글 맵에서 text가 있는 image와 없는 image를 학습시켜서 text가 있는 이미지에서 어디 부분에서 activation이 되는지를 전부다 Weakly-supervised로! 어떻게 어디가 activation이 되었는지를 깔끔하게 보여준다.
결론적으로 CAM은 굉장히 유용한 tool이 될 것이라고 생각되고 weakly-supervised learning이 실제로 잘 되는 것을 보면서 다른 문제에서도 어떻게하면 weak label로 우리가 풀고 싶은 더 어려운 문제를 풀까 고민을 잘 해봐야겠다.
신기한건 Fully-connected에서도 가능하다. 1x1 conv라고 생각하면 똑같을 수도 있지만 어쨌든 ↩︎