프로그램 실행 관점에서 본 windows 와 linux의 차이


본 포스트는 프로그램의 실행 관점에서 어떻게 windows 와 linux가 다른지에 대해 얘기하고자 한다.
그리고, 다음 포스트에서 그 차이를 어떻게 맞출 수 있는지에 대해 설명하고자 한다.
Ubuntu와 같은 Linux 배포판을 처음으로 사용하게 되면,
너무도 당연하게 돌던 것들이 안돌아서 당황하기 마련이다.
(Ex. 카톡, 게임, 오피스 등등.)
필자도 대학생때 처음으로 ubuntu 를 설치해보고 그랬다. 그래도, 요즘에는 크로스플랫폼이 대세라 꽤나 많이 도는 것 같다. (그런데 카톡은 왜! 웹버전도 없는가!!)
그리고, 검색해서 찾아보면 모두들 Wine 쓰라고 한다.
Wine 을 설치하면, 게임을 제외한 대부분의 것들이 실행되기 때문에 아주 편-안 하다.
요즘에는 steam 에서 wine을 개조해서 많은 게임들을 돌려주고 있고, wine도 3d쪽 개발에 많은 힘을 쓰고 있다.
그렇다면, wine은 어떻게 linux에서 windows 앱들을 돌리는 것일까?
차이점부터 알고, 어떻게 구현을 했는지 알아보자.
1. 실행 파일(.exe, .dll, .so)의 차이
첫째로 바이너리의 형식부터 다르다.
Windows의 PE
Windows의 바이너리 파일들의 형식은 PE (Portable Executable)이라고 부른다.
.exe와 동적 library인 .dll 포함 그 외에 다양한 확장자들 (.ocx, ...) 들 모두 다 PE 이다.
PE 파일을 딱 까보면, MZ 라는 글자로 시작한다.
(제작자인 Mark Zbikowski 의 약자라고 한다 ㅋㅋㅋ)
포맷에 맞게 파싱을 해서 편하게 봐보자!
물론 직접 할 필요는 없다. CffExplorer, PEView 등등 툴이 많다.
(나는 필요성이 있어서 직접 다 구현했다... ;;)
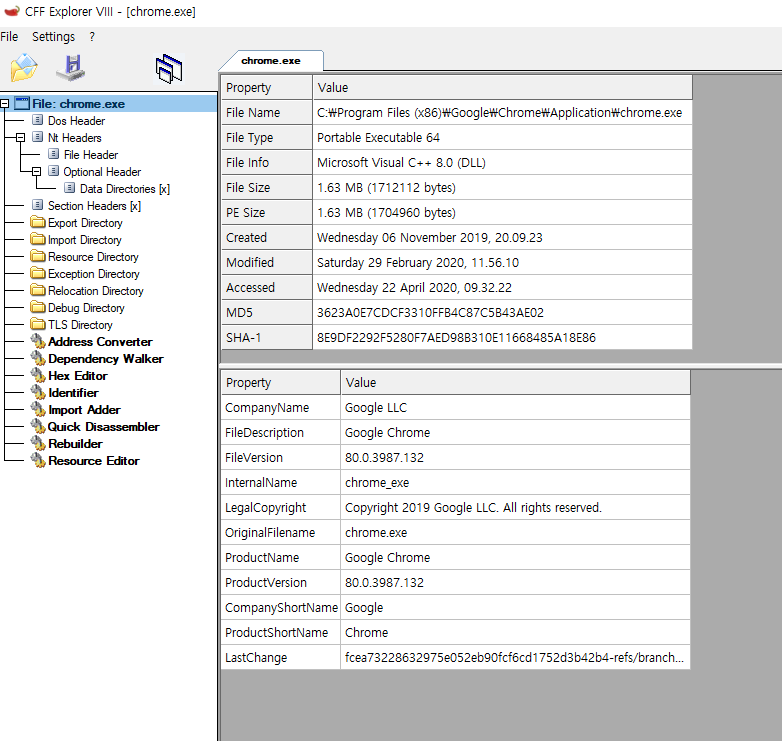
chrome.exe 를 까본 첫 화면이다. PE Header 를 통해 저런 정보들을 알 수 있따. 80.0.3987.132 버전이고, 구글이 만들었고, 2019.12.06 에 만들었고 등등.
뭐 사실 이런 것들은 부수적인 정보일 뿐이긴 하다.
프로그램 실행의 관점에서 필요한 것들을 한번 살펴보자.
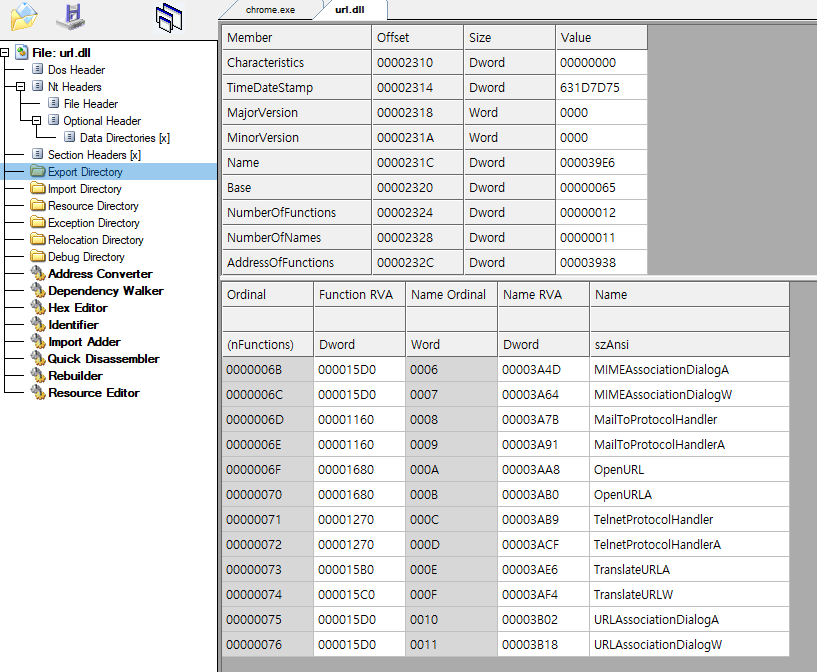
이번에는 windows/system32/url.dll 을 까본 내용이다.
그 중에서 export directory 를 본 것이다.
Export directory 에는 url.dll 의 함수들 중에서 남들이 호출해서 사용할 것들이 써져있다.
function 이름, 번호, 주소가 써져있어서, 사용하고자 하는 함수의 이름만 알면 여기서 찾아서 호출할 수 이따.
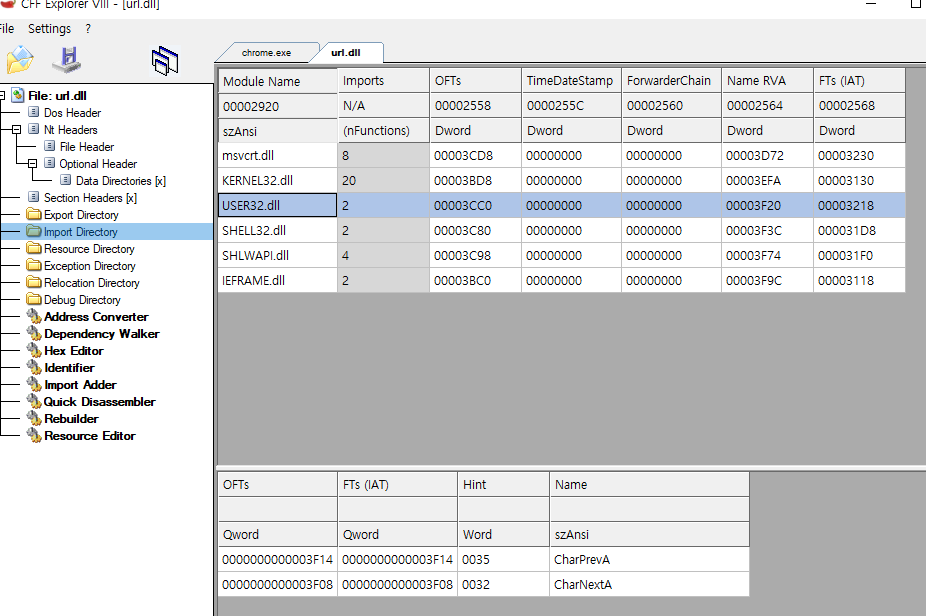
이번에는 import directory 이다.
import directory 는 url.dll 이 사용하는 다른 dll 의 함수들이다.
위의 사진을 보면 msvcrt, kernel32, user32, shell32, shlwapi, ieframe 을 사용하고 있다는 것을 알 수 있다.
그 중에서도 user32 를 보면, CharPrevA, CharNextA 두 함수를 사용하는 것을 알 수 있다.
url.dll 이 어떤 외부 함수들을 써서 구현했는지 다 알 수 있다!!.
(물론, 동적으로 로딩하는 방법을 이용해 다른 dll들을 사용했을 수도 있긴 하다...)
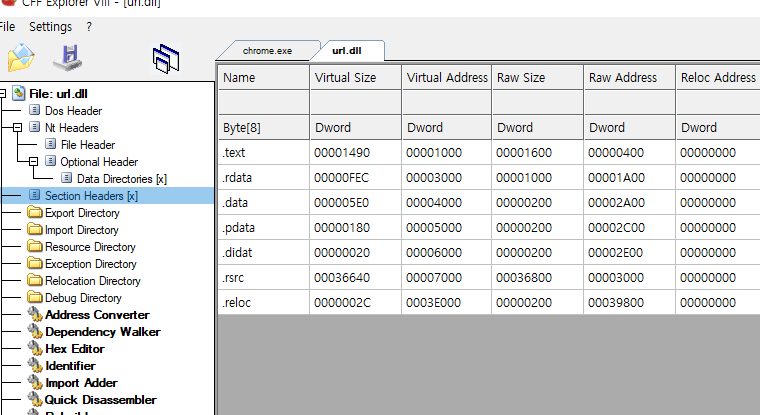
이번엔 section header 이다. 여기 또 특이점이 있다.
위의 export directory 나, import directory, 실제 코드들 등등의 정보는 각 섹션에 담겨있다.
섹션헤더를 보면 섹션 정보들이 나와있는데, virtual address 랑 raw address 가 있다. 왜 두개나 있는가?
포맷이 완전히 달라도 사실 내용물들은 크게 다르지 않는데,
이것이 elf 와의 가장 큰 차이점 중 하나다.
Windows 는 실제로 해당 binary를 memory에 올릴 때, 파일을 그대로 올리지 않고, virtual address 에 맞춰 올린다. (극혐. 스토리지가 부족하던 시절에 만들어져서 그런가.)
PE파일에서 각 섹션들을 raw address 보고 찾아내서, 조각조각 잘라진후 virtual address 에 맞춰 그 위치로 올라간다.
그리고, 그 offset 들은 alignment 가 0x1000 단위이다.
이 외에도 entry point (main의 주소)나, 각종 리소스(아이콘 등)들, 그 외 무수한 정보들이 담겨있다.
Linux의 ELF
Linux 에서 사용하는 대부분의 바이너리 파일들은 ELF (Executable and Linkable Format) 이다.
역시 파일을 까보면 시작이 ELF 이다.
(base) jonhpark@jonhpark-home:~$ xxd /bin/ls | head
00000000: 7f45 4c46 0201 0100 0000 0000 0000 0000 .ELF............
00000010: 0300 3e00 0100 0000 5058 0000 0000 0000 ..>.....PX......
00000020: 4000 0000 0000 0000 a003 0200 0000 0000 @...............
00000030: 0000 0000 4000 3800 0900 4000 1c00 1b00 ....@.8...@.....
00000040: 0600 0000 0500 0000 4000 0000 0000 0000 ........@.......
00000050: 4000 0000 0000 0000 4000 0000 0000 0000 @.......@.......
Linux 시스템에서는 사실 확장자가 큰 의미가 없다. 그냥 사람들이 읽기 편하라고 붙여줄 뿐이다.
(Windows는 확장자가 파일을 인식하는 첫번째 표시라서 올바른 확장자가 붙어있어야 한다.)
보통 실행파일은 확장자가 없고, 동적라이브러리들은 .so인데, 모두 다 ELF이다.
ELF 는 Linux 터미널에서 readelf 명령어를 통해 쉽게 파싱에서 볼 수 있다.
(base) jonhpark@jonhpark-home:~$ readelf -h /bin/ls
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Shared object file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x5850
...
(base) jonhpark@jonhpark-home:~$ readelf -S /bin/ls
There are 28 section headers, starting at offset 0x203a0:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000000238 00000238
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.ABI-tag NOTE 0000000000000254 00000254
0000000000000020 0000000000000000 A 0 0 4
[ 3] .note.gnu.build-i NOTE 0000000000000274 00000274
0000000000000024 0000000000000000 A 0 0 4
[ 4] .gnu.hash GNU_HASH 0000000000000298 00000298
00000000000000ec 0000000000000000 A 5 0 8
[ 5] .dynsym DYNSYM 0000000000000388 00000388
0000000000000df8 0000000000000018 A 6 1 8
[ 6] .dynstr STRTAB 0000000000001180 00001180
0000000000000682 0000000000000000 A 0 0 1
[ 7] .gnu.version VERSYM 0000000000001802 00001802
000000000000012a 0000000000000002 A 5 0 2
...
대충 이러하게 생겼다. 너무 많아서 아래는 그냥 생략.
생긴 것을 보면 그게 다르지는 않다.
헤더에 각종 정보, entry point 등등이 있고,
섹션을 보면 심볼들(.dynsym) 이 있다.
특이한 점은 스트링 정보가 각각 위치에 있는 것이 아니라 한쪽에 다 몰려있다. (strtab)
여기서 windows 와 다른 점은(!) 사용하는 함수(심볼)가 어느 파일에서 가져오는지가 명시 되어 있지 않다.
그냥 아무데서나 찾아온다.
(진짜 아무데서나는 아니지만, 명시된 규칙을 찾을 수 없었고, glibc 코드를 보고서야 알아냈다. 아마도 구현체따라 다른 것 같다.)
어쨌든 이런 구조는 예기치 못한 문제들을 야기한다.
같은 이름의 함수가 여기저기 있는 경우. 제대로 잘 찾아오기를 비는 수 밖에 없다.
(명시적으로 함수포인터를 얻어와서 호출하는 방법이 있다.)
필자는 이런 경우들을 많이 대규모 프로젝트에서 이런 경우를 많이 목격 했는데, 시스템이 정비되기 전까지는 암 걸린다. 정말.
이 내용은 나중에 따로 더 자세히 다루겠다.
PE와 다르게 offset 그대로가 파일에서의 offset이라 그냥 fd 를 메모리상에 mmap 해도 된다.
로더의 구현 관점에서 아주 편하다.
결론
위에 나열한 차이점들이 있다.
Windows 에서 elf 를 돌리거나, linux에서 PE를 돌리는 경우에, 각 포맷에 맞는 맞춤형 로더&링커가 필요하다.
2. Process 구조의 차이
실행 파일은 이제 알았고, 실제 파일을 실행시키면 어떤 차이들이 더 있을까.
Memory Layout
첫째로 메모리 레이아웃이 다르다...
Windows는 아직도 32bit 프로세스가 대부분이니 32bit을 기준으로 비교해보자.
컴퓨터관련 전공자들을 익히 보았을 linux 프로세스의 메모리 레이아웃이다.
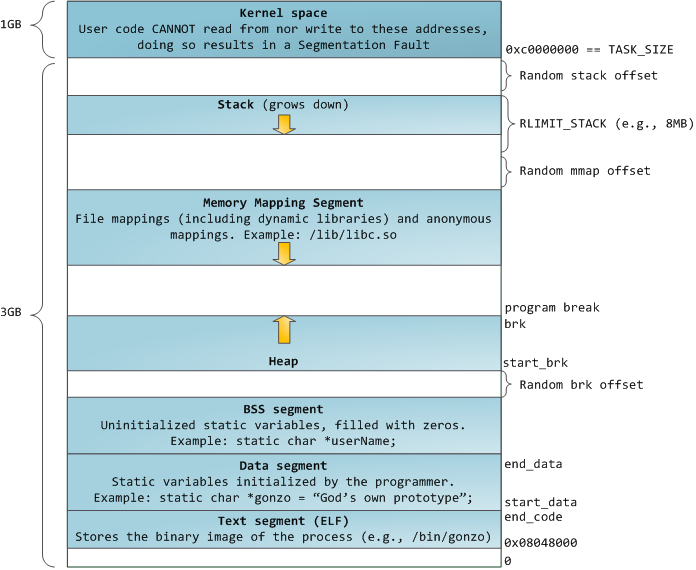
총 4G 의 virtual address space 중에서 3G - 4G 영역은 kernel의 것이다.
그래서, 내가 프로그램을 만들어서 아무리 짜봐야 3G 이하의 주소만 사용가능하다.
Windows의 구조를 보자.
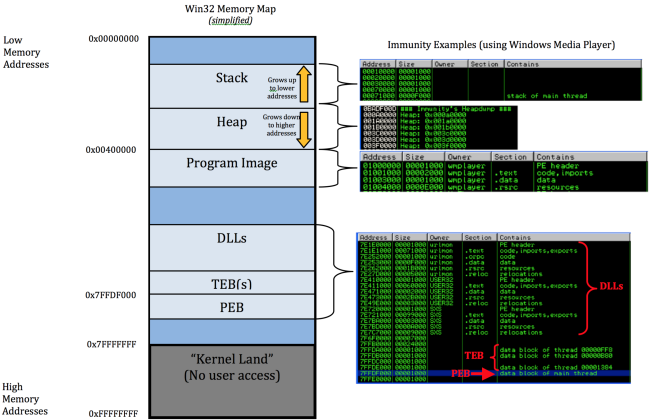
(linux그림이랑 방향이 반대이긴한데..;;)
2G - 4G 영역이 windows kernel의 것이다.
무려 1G 나 차이가 난다.
Stack 의 위치도 다르다. 0x400000 아래쪽으로.
linux에서의 stack은 0xc0000000 근처에 존재한다.
Heap 위치도 다르다.
Global 구조체
x86 기준 windows 프로세스는 fs 레지스터에 TEB (Thread Environment Block) 주소가 박혀있다.
그래서, 실행중이라면 언제든지 Fs 레지스터에 접근하여 TEB 구조체를 가져오고, 이어져있는 모든 정보들을 열람 가능하다.
Fs 레지스터를 이런 곳에 사용한다는 것이 놀랍다.
이 덕분에, linux 버그를 찾아내기도 했다. (전 포스트 참조)
TEB를 통해 접근할 수 있는 것들에는 PEB, ldr modules, tls 등등 이 있다.
물론 비슷한 것들이 linux에도 대부분 있다.
예를 들어, ldr module 은 각 "메모리에 올라간 PE 파일"을 추상화(?) 한 것인데, libc 에는 "메모리에 올라간 elf 파일"을 추상화한 link_map 이라는 구조체가 있다. 역할도 비슷하다.
Process/Thread 를 위한 global 구조체들의 생김새나, 저장위치, 접근하기 위한 api 등에 차이가 있다.
3. Loader & Linker 가 해야할 일
위와 같은 차이로 인해서, Loader & Linker 가 해야할 일들이 달라졌다.
Program의 Execution Flow 를 간단히 생각해보자.
Windows 에서는
CreateProcess API가 호출되면,
- Kernel이 프로세스를 생성하고
- Loader 가 .exe를 올리고, 필요한 dll들을 올린다.
- Linker 가 EAT, IAT 를 참조하여 linking 을 수행한다.
- 각 ldr module을 attach 하고, global 구조체들을 구성한다.
- User program 의 코드 (main)을 호출한다.
Linux 에서는
Fork & exec 이 호출 되면
- Kernel이 프로세스를 생성하고,
- Loader 가 main binary 를 올리고, 필요한 .so 들을 올린다.
- Linker 가 linking 을 수행한다.
- 각 link_map 의 constructor 들을 호출하고, global 구조체들을 구성한다.
- User program 의 코드 (main)을 호출한다.
이렇게만 보면, 큰 흐름은 거의 같다.
Windows에서의 Loader&Linker는 kernel, ntdll, kernel32에 적절히 구현되어 있는 것 같다.
Linux에서의 Loader는 kernel과 libc, Linker는 libc에 구현되어 있다.
기본적으로 libc는 glibc를 사용하지만 마음대로 교체할 수 있고, kernel 쪽에도 모듈을 심어서 마음대로 끼워 넣을 수 있다. 물론, Kernel 부터 뜯어고쳐도 된다.
단계별 차이점을 보자면,
Loader: Activation Context
Loader 가 적절한 파일 (PE, Elf) 를 파일 시스템에서 찾는 과정에서 차이가 있다.
둘 다 어딘가에 등록된 것을 바탕으로 찾는데, windows는 추가적으로 activation context를 참조한다.
Windows 는 버전관리에 매우 애를 먹었었다. Dll Hell 라고 불리우는데, 같은 이름의 dll이라 하더라도 버전마다 API도 구현체도 다르니....
그래서, 생긴 개념이다. Winsxs 폴더에 적절한 각 버전의 dll들을 넣어두고, .exe 또는 xml 파일을 읽어서 특정 버전을 읽어오라고 지시하는 개념이다. (매우 그지같다.)
동적으로 껐다 켰다도 가능하다.
Linux에서도 동적으로 경로를 지시해서 읽어오는 것이 가능은 하다만, elf에 이런 정보들이 박혀있거나 하지는 않다. 시스템 구성하는 자가 알아서 잘 구성을 해두어야 한다.
Linker: Lazy Binding
당연하게도, linking 방식에도 차이가 있다.
가장 큰 차이점은 기본 방식이 lazy하느냐 아니냐 이다.
Linux에서는 lazy 하다. 주소를 미리 찾아두지 않고 함수가 호출이 되면 그제서야 찾는다.
Plt 에는 libc의 resolve 함수 주소가 박혀있어서, 함수가 호출되면 그제서야 주소를 찾아나선다.
그리고, 찾아진 함수의 주소를 덮어써서 다음에는 찾을 필요가 없도록 한다.
plt & got 관련한 elf 의 linking 로직은 여기 에 설명이 잘 되어있으니 궁금한 사람들은 한번 보시라.
Windows에서는 그냥 다 찾는다. 찾아서 박아둔다. 찾고자 하는 함수가 어느 dll에 있는지 까지 명시가 되어있다.
해당 dll파일이 EAT 를 보고 주소를 찾아온 후 내 IAT에 그 주소를 박아준다.
EAT (export address table)은 위에서 설명한 export directory 이다. 내 PE 중에서 아무나가 사용할 수 있도록 공개한 함수 이름과 주소들이 써져있는 테이블.
IAT (import addres table)은 위에서 설명한 import directory 이다. 내 PE가 호출할 함수들. 파일 상태에서는 주소들이 당연히 비어있다. 하지만 실행 중에는 내가 사용할 dll들이 이미 메모리에 올라와있기 때문에, linker가 이 함수들의 위치를 다 찾아서 주소를 적어둔다.
함수가 호출될때는 이 IAT를 보고 가면 바로바로 함수를 호출할 수 있다.
실제로 빌드를 하면 코드가 다 iat를 보고 찾아가도록 생성된다.
이 외에도 각 dependency들을 불러 올릴때, bfs 순서로 올리냐 dfs 순서로 올리냐의 차이도 있다.
다른 사소한 차이점들이 더 있지만, 우선 이정도로 마무리 하고자 한다.