LSTM 과 ResNet

서론
우선 LSTM은 최근에 나온 개념이 아닙니다. 이미 1997년 [Hochreiter et al., 1997]에서 나온 개념이며 기존 RNN(Vanilla Recurrent Neural Network)가 오래전 정보를 잊어버리는 단점을 보완했습니다. LSTM의 기본 배경지식을 다 설명하면 좋겠지만, 이 글은 기본적으로 LSTM이 어떻게 작동하는지 ResNet은 무엇인지 예전에 공부하던걸 옮겨논 것입니다.
이 글은 저의 순수한 창작물이 아니며 다음 자료들을 바탕으로 쓰여졌습니다.
- LSTM의 개념
- Standford CS231n 강의노트 및 영상
- LSTM을 쉬운 그림으로 설명하는 Colah's blog, T-Robotics의 우리말 번역
- LSTM이 무엇인지 쉽게 설명하고 Theano 구현을 살펴본 WildML 그리고 우리말 번역의 AI Korea 블로그 포스트
- LSTM Backpropgation을 해석한 AIDAN GOMEZ Blog
- LSTM의 구현
- Torch의 nngraph을 이용한 LSTM의 쉬운 torch implementation
- Karpathy의 char-rnn 그리고 이것을 바탕으로 쓴 Karpath의 블로그 포스트
- 위의 char-rnn에서 구현된 LSTM의 학습 시간과 메모리를 개선한 Justin Johnson의 torch-rnn
LSTM

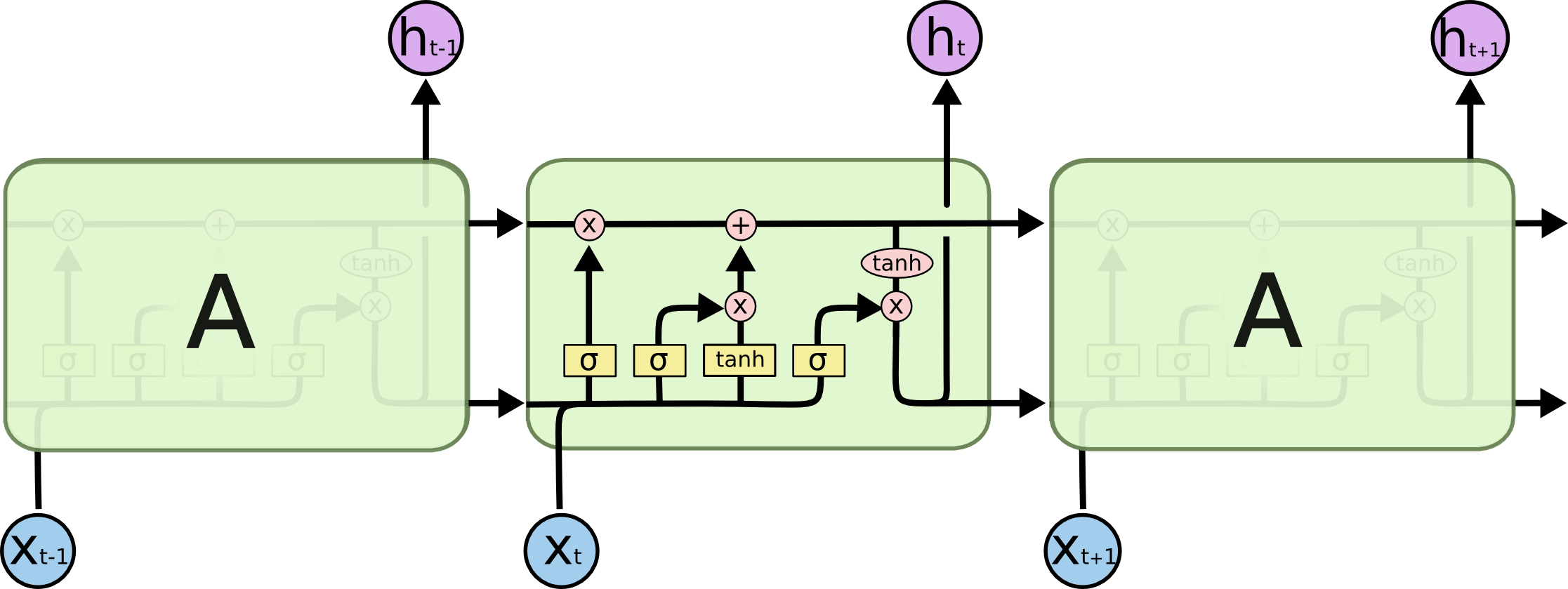
원래 RNN은 이렇게 생겼습니다. 오른쪽은 그냥 그것을 펴낸 것이고 input에 곱해지는 U, hidden state에 곱해지는 W, 그리고 output의 V입니다. 이렇게 input, hidden state를 U, W등으로 직접적으로 바꿔 주는 것은 학습과정의 Back-propgation에서 잘못된 gradient에 매우 취약합니다. 따라서 LSTM은 이것을 Gating mechanism으로 풀어냅니다.
LSTM은 다음과 같이 생겼습니다.
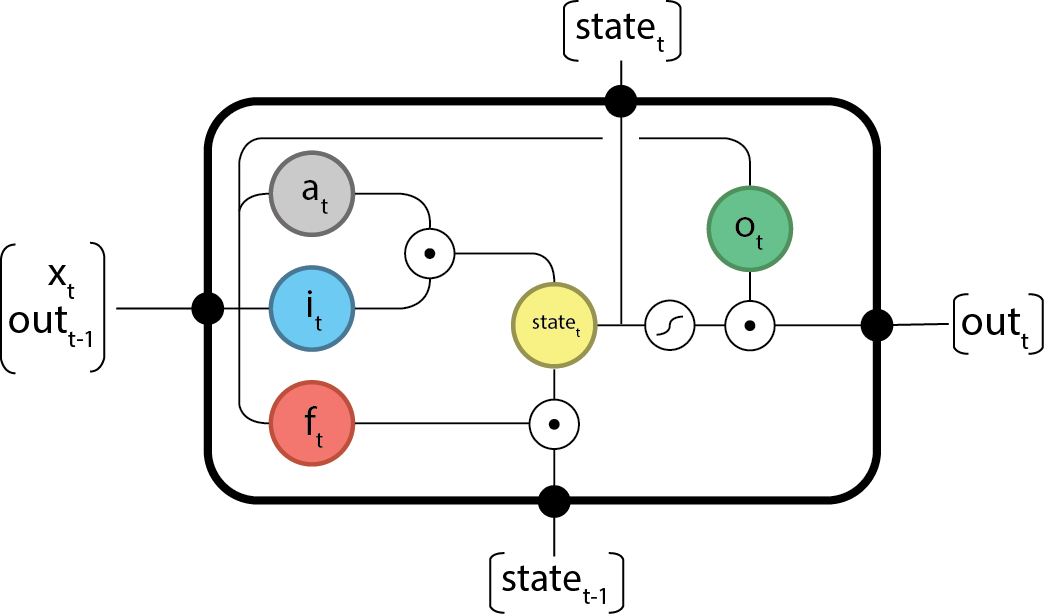
출처: 일단 이 그림에서 computation이 어떻게 일어나는 지는 위의 참고자료들을 참고부탁드립니다. 어쨌든 LSTM의 computation들은 Cell state를 중심으로 일어납니다. 그리고 각 LSTM module들은 input, previous cell state, previous output로 새로운 cell state, output을 계산합니다.
-
Input activation:
\begin{equation}
a_{t} = \tanh(W_{a} \cdot x_{t} + U_{a} \cdot out_{t-1} + b_{a})$
\end{equation} -
Input gate:
\begin{equation}
i_{t} = \sigma(W_{i} \cdot x_{t} + U_{i} \cdot out_{t-1} + b_{i})
\end{equation} -
Forget gate:
\begin{equation}
f_{t} = \sigma(W_{f} \cdot x_{t} + U_{f} \cdot out_{t-1} + b_{f})
\end{equation} -
Output gate:
\begin{equation}
o_{t} = \sigma(W_{o} \cdot x_{t} + U_{o} \cdot out_{t-1} + b_{o})
\end{equation}
우선 LSTM이 Vanilla RNN과 어떻게 다른지 간략히 설명하겠습니다.
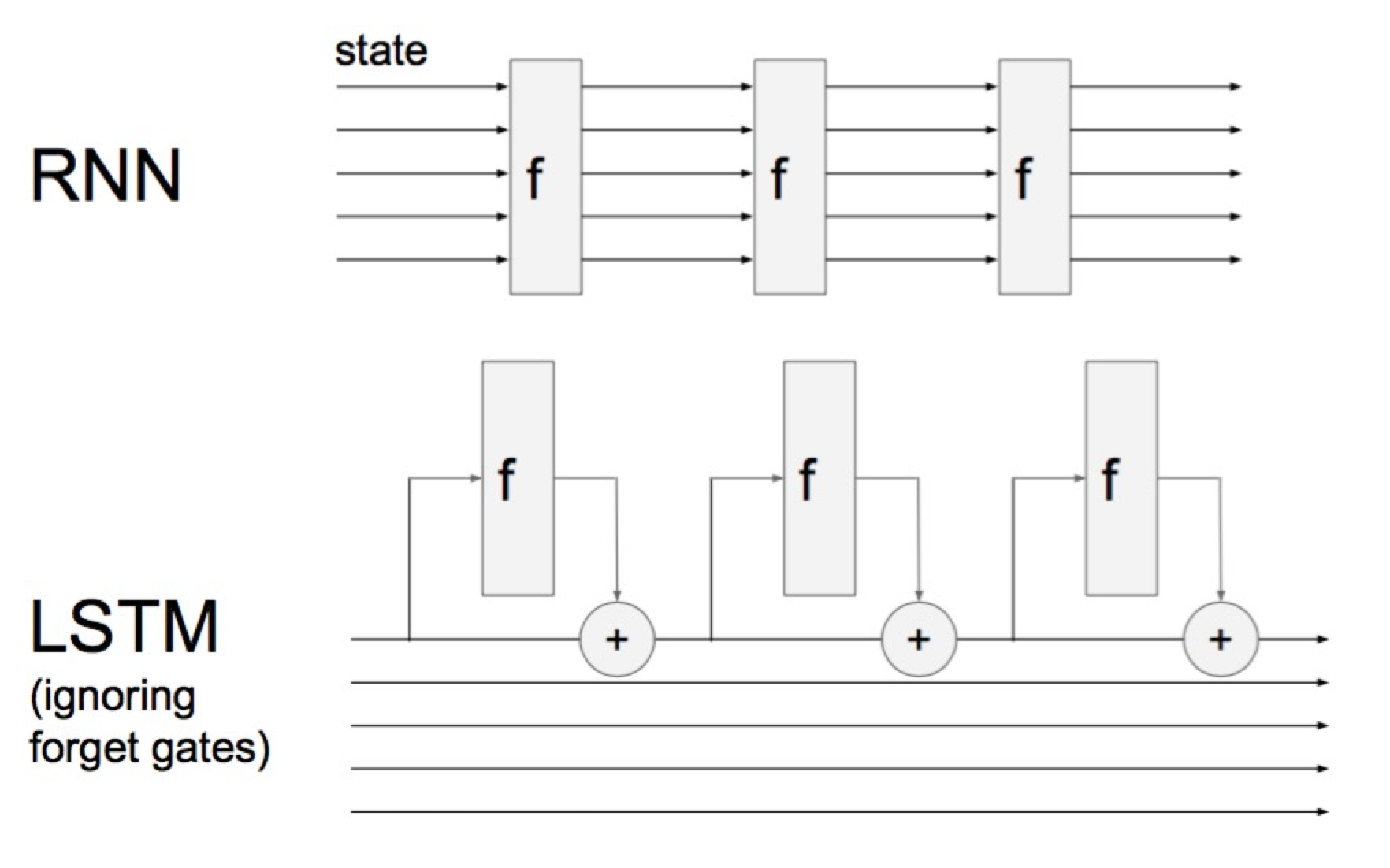
이 그림은 cs231n의 RNN 강의 에서 가져왔습니다. Vanilla RNN은 위와 같이 hidden state를 Neural Network로 완전히 transformation을 합니다. 따라서 hidden state vector가 time step마다 바뀝니다.
하지만 LSTM은 hidden state 외에 cell state를 가지고 있습니다. 그리고 이 cell state가 계속 끝까지 흘러가는 형태입니다. 일단은 forget gate가 없는 LSTM이라고 생각해봅시다. 매 time step에 cell state가 Neural Network안에 leak이 되어 hidden state 그 cell state를 보고 computation을 하고 cell state를 additive하게 업데이트합니다. 즉 Vanilla RNN이 hidden state를 transformative하게 바꾸는 것에서 차이점이 있습니다.
그래서 마지막에 Back propagation으로 gradient 업데이트를 할때 이 gradient는 LSTM 구조에서 초기 input 끝까지 흘러들어갑니다. 그리고 각 f도 나름 gradient를 계산해서 additive하게 더해주죠. Karpathy는 이를 Gradient super highway라고 표현했습니다. 결론적으로 gradient가 죽어버리는 gradient vanshing 문제가 일어나지 않습니다.
RNN vs LSTM gradients on the input weight matrixError is generated at 128th step and propagated back. No error from other steps. At the beginning of training. Weights sampled from Normal Distribution in (-0.1, 0.1).
ResNet
이런 개념은 사실 ILSVRC 2015에서 뛰어난 성능을 보여준 ResNet과 비슷합니다.

ResNet도 Activation을 직접적으로 transformation하는 weight를 학습하는게 아니라 input과 ouput의 차이인 residual을 학습시키는 방식입니다. 즉 기존 AlexNet, VGG, GoogLeNet은 Convolution을 통해 Tensor (Feature maps)를 Transformation 시켜왔지만 ResNet은 input에 Additive한 값을 Conv로 학습시킵니다. Gradient가 additive하게 흐르는 것을 Skip connection 등으로 논문에서 표현합니다. 이는 아까 LSTM의 gradient highway랑 비슷한 말이죠.
ResNet의 장점은 원활한 gradient flow로 인해 VGG19가 VGG16보다 성능이 안좋은 것처럼, CNN의 깊이가 깊어질수록 학습이 어렵고, 오히려 성능의 하락했던 것을 해결했습니다. ResNet은 깊이가 152까지 되는 등 어마어마하죠. 그리고 성능은 훨씬 더 좋습니다.[1]
여기에 부가적으로 CNN을 깊게 쌓으면서, Fully Connected layer를 떼어내었습니다. 이건 모델의 parameter 수를 줄이는데도 도움이 되었지요. (Conv가 FC보다 parameter수가 훨씬 적습니다.)
Kaiming He가 벌써 제안된지 1년이 되가는 ResNet (Deep Residual Learning for Image Recognition arXiv:1512.03385v1) 은 이후 Identity Mappings in Deep Residual Networks (ECCV2016)에서 Conv, Batch Normalize, ReLU의 순서를 달리하면서 Gradient flow를 더 개선시키기도 했습니다.
이는 또 Torch blog에서 ResNet의 단순 구조 변화가 성능을 올린다는 것을 보였지요.
결국 두 모델의 비슷한 점은, Gradient가 Additive함으로써 더 원활하게 흐르는 것이, Optimization 측면에서도 좋으며 Gradient Vanishing/Exploding 문제를 해결해낸 것입니다.
꼭 깊어진다고 성능이 좋아지는 것이 아니라고 합니다. "Wide Residual Networks"에서는 ResNet을 깊이를 낮추고 wide하게 하는 것이 성능이 더 좋다고 합니다. Residual block이 더 성능에 중요한 것이라네요. ↩︎