StarGAN : Image Translation with GAN (6)


StarGAN : accepted as CVPR2018 oral presentation.

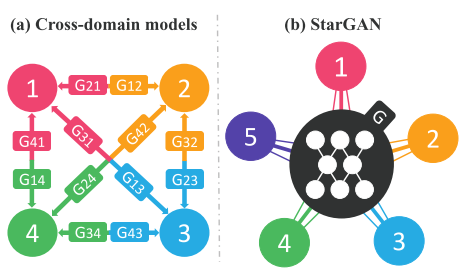
(a) Each domain shift needs generators. (b) Share one generator and use latent code of each domain
The previous limitation of pix2pix, DTN, CycleGAN & DiscoGAN, BicycleGAN is that they only handle two domains: the source and the target. But, there are multi-domains in general. Not only summer & winter, there are spring and fall. With $n$ domains, It's not practical to learn all $n(n-1)$ generators.
Contribution
- GAN that learns the mappings among multiple domains using only a single generator and a discriminator, training effectively from images of all domains.
- Successfully learn multi-domain image translation between multiple datasets by utilizing a mask vector method that enables StarGAN to control all available domain labels.
- Provide both qualitative and quantitative results on facial attribute transfer and facial expression synthesis tasks using StarGAN, showing its superiority over baseline models.
Overview
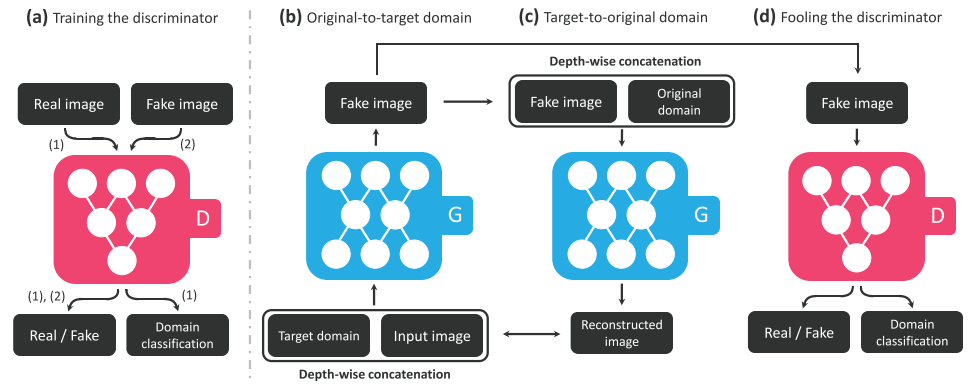
- Translate an input image $x$ into an output image $y$ conditioned on the target domain label $c$.
- When training, translate $y$ back to $x$ with given orginal domain label $c'$.
- $D_{src}(x)$ as a probability distribution over sources given by $D$
\begin{equation}
D:x \rightarrow ({D_{src}(x), D_{cls}(x)})
\end{equation}
Discriminator produces probability distributions over both sources and domain labels.
\begin{equation}
G(x,c) \rightarrow y
\end{equation}
Adversarial Loss
\begin{equation}
\mathcal{L}_{adv}=\mathbb{E}_x[\log D_{src}(x)] + \mathbb{E}_{x,c}[\log(1-D_{src}(G(x,c)))]
\end{equation}
Add auxiliary classifier on top of $D$, ACGAN
Domain Classification Loss
A domain classification loss of real images used to optimize $D$
\begin{equation}
\mathcal{L}^r_{cls}=\mathbb{E}_{x,c'}[-\log D_{cls}(c'|x)]
\end{equation}
- $D_{cls}(c'|x)$ : a probability distrbution over domain labels computed by $D$
- input image and domain label pair $(x,c')$ given by training dataset
- $D$ learns to classify a real image $x$ to its corresponding original domain $c'$
A domain classification loss of fake images used to optimize $G$
\begin{equation}
\mathcal{L}^f_{cls}=\mathbb{E}_{x,c'}[-\log D_{cls}(c|G(x,c))]
\end{equation}
- identical to $\mathcal{L}^f_{cls}=\mathbb{E}_{x,c'}[-\log D_{cls}(c|y)]$ by $G(x,c) \rightarrow y$
- $G$ minimizes $\mathcal{L}^f_{cls}$ to $y$ classified as target domain $c$
Reconstruction loss
\begin{equation}
\mathcal{L}_{rec} = \mathbb{E}_{x,c,c'} [||x - G(G(x,c),c')||_1]
\end{equation}
Note that a single generator used twice.
Full Objective
\begin{equation}
\mathcal{L}_{D}=-\mathcal{L}_{adv}+ \lambda_{cls}\mathcal{L}^r_{cls}
\end{equation}
\begin{equation}
\mathcal{L}_{G}=\mathcal{L}_{adv}+\lambda_{cls}\mathcal{L}^f_{cls}+\lambda_{rec}\mathcal{L}_{rec}
\end{equation}
$\lambda_{cls}=1, \lambda_{rec}=10$
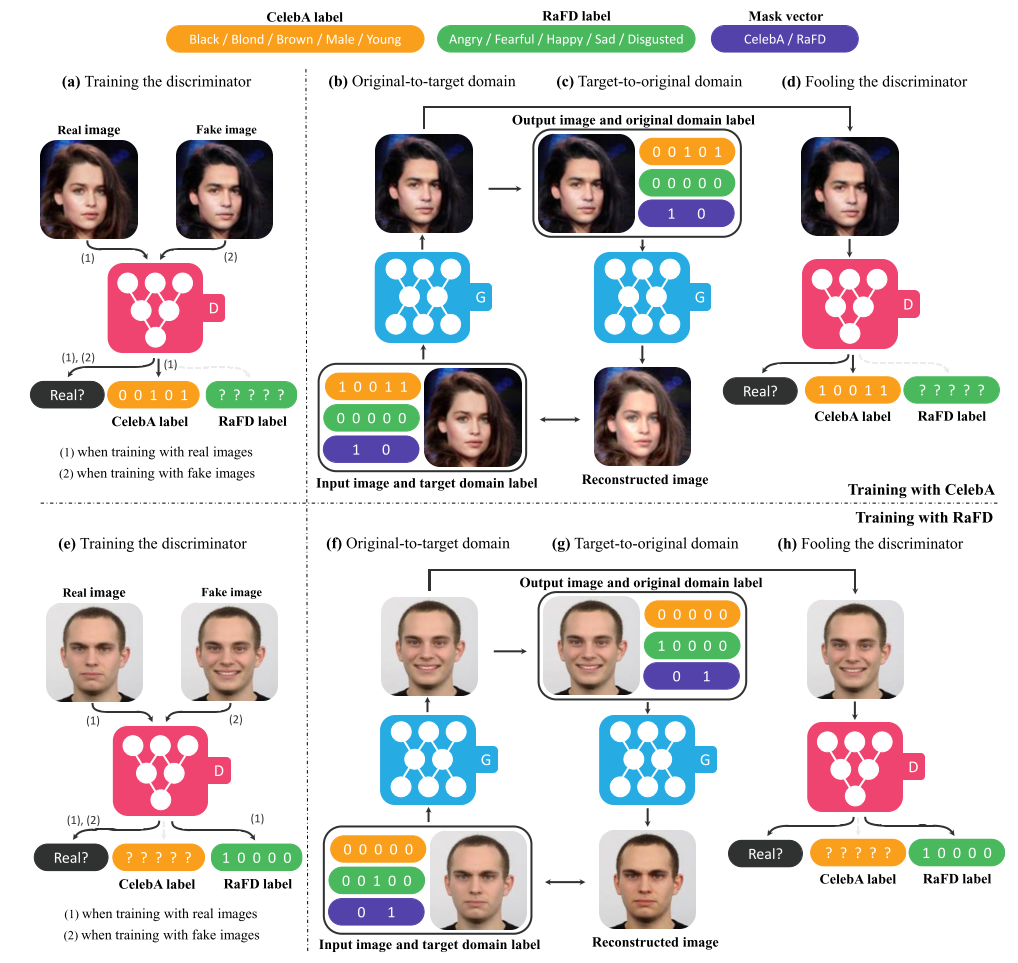
Training with Multiple Datasets
StarGAN simultaneously incorporates multiple datsets of different types of labels (gender/hair color and facial expression). An issue when learning from multiple datasets, however, is that the label information is only partially known to each dataset.
CelebA : hair color and gender, RaFD : facial expressions
Label vector $c'$ is required when reconstructing the input image $x$ from the translated image $G(x, c)$ (See $\mathcal{L}^f_{cls}$). Mask vector $m$ allows StarGAN ignore unspecified labels.
$n$ : # of datasets, $m$ is $n$-dim one-hot vector
Unified label $\tilde{c}=[c_1, ... , c_n, m]$, all concatenated, here with 2 datasets, $n=2$.
$G$ learns to ignore the unspecified labels... wich are zero vectors focus on the explicitly given label.
Extended auxiliary classifier of the $D$ over labels for all dataset. Only minimize to the know label.
Implementation
Replace Vanilla GAN loss $\mathcal{L}_{adv}$ with Wasserstein GAN with gradient penalty.
\begin{equation}
\mathcal{L}_{adv} =\mathbb{E}_x [D_{src}(x)] - \mathbb{E}_{x,c} [D_{src}(G(x,c))] - \lambda_{gp}\mathbb{E}_{\hat{x}} [(||\nabla_{\hat{x}} D_{src}(\hat{x})||_2 - 1)^2]
\end{equation}
$\lambda_{gp} = 10$ and $\hat{x}$ is sampled uniformly along a straight line between a pair of a real and generated images.
Structure from CycleGAN, 2 Convs of 2-strided, 6 ResBlock, 2 Deconv of 2-strided.
Instance Norm for $G$ no norm for $D$, leverage PatchGANs (sec7.2).
Experiments
3 types of experiemtns.
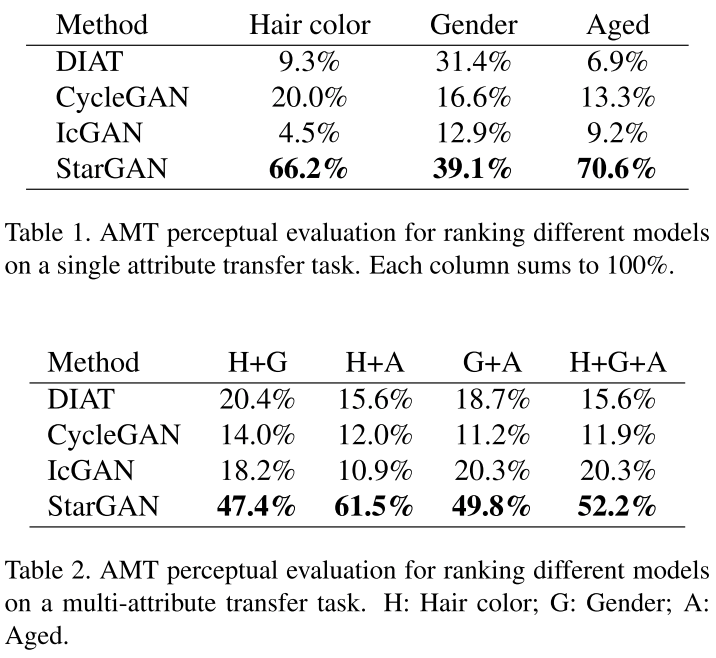
- Compare recent methods on facial attribute transfer by user studies
- DIAT, CycleGAN, IcGAN (cGAN). Trained multiple models for every pair of two different domains.
- Classification experiment
- Empirical results that StarGAN can learn image-to-image translation from multiple dataset
CelebA
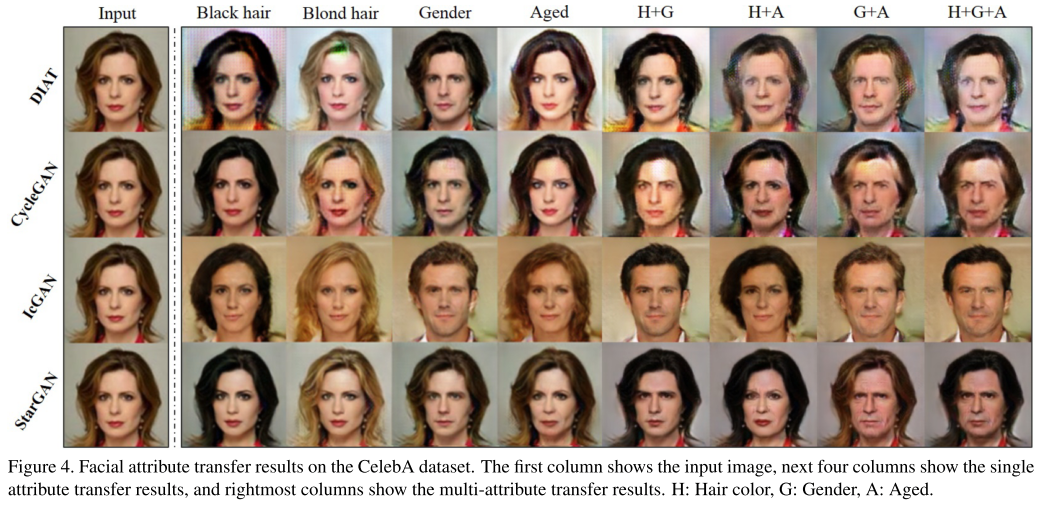
H+G : cross domain models like DIAT, CycleGAN transfer over again. H then G.
One possible reason is the regularization effect of StarGAN through a multi-task learning framework. In other words, rather than training a model to perform a fixed translation (e.g., brown- to-blond hair), which is prone to overfitting. This allows model to learn reliable features universally applicable to multiple domains of images with different facial attribute values.
Transfer in gender : DIAT, StarGAN are similar but G+A shows significant. StarGAN handles multi-attribute transfer tasks, trained to randomly generating image of a target domain label.
RaFD

Superiority of StarGAN in the image quality is due to its implicit data augmentation effect from a multi-task learning setting. (Good explanation but not verified.)
RaFD images contain a relatively small size of samples, e.g., 500 images per domain. When trained on two domains, DIAT and CycleGAN can only use 1,000 training images at a time, but StarGAN can use 4,000 images in total from all the available domains for its training. This allows StarGAN to properly learn how to maintain the quality and sharpness of the generated output.
Similar to the concept how "Google Translate" learns human language by training multiple languages together and map into some what central lanuage feature space. But still, not fully verified.
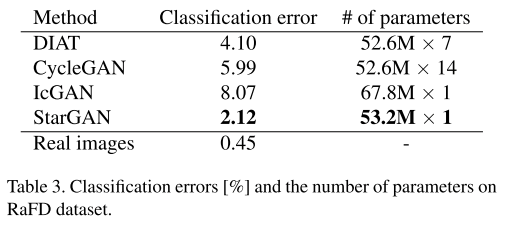
CelebA + RaFD
- StarGAN-SNG (Single) only on RaFD, StarGAN-JNT (Joint) on CelebA and RaFD.
- StarGAN-JNT can leverage both datasets. By utilizing both CelebA and RaFD, StarGAN-JNT can improve these low-level tasks, which is beneficial to learning facial expression synthesis.


- $m$ mask vector wrongly applied on second row.
- 'Young' attribute is masked thus became old.
Appendix

My thought
Actually, StarGAN not only deals with multi-domains but also multi-attributes. Thus it is more impressive and general setting, because domains can't be overlapped but attributes can be.
Masking vector is a little bit wierd but works good in practice.
I still wonder how StarGAN, which I think it as a good assemble of cGAN + ACGAN, produces such high quality results. Maybe I underestimated the power of GAN, and using auxiliary classifier to augment dataset approach helped GAN training a lot. Generator might indeed learned the data distribution better than those in CycleGAN, or changing face might be easy problem for GAN.
To be fair, we also need to try CycleGAN with single generator concept as StarGAN and apply on other dataset (day2night, horse2zebra). Then, see if StarGAN concept really avoid overfitting and make reliable features universally applicable to multiple domains of images with implicit data augmentation.