딥러닝 기반 서비스 구축하기


최근에 딥러닝 기반 서비스를 바닥부터 다 만든 일이 있었다. 만들고 시범 운영을 해보면서 느낀 점, 구현하면서 생각해 볼 만한 점들을 정리해보았다.
문제 정의
차량의 주행 및 소음진동 정보를 기반으로 차량의 상태를 진단하자. 이번에 딥러닝 모델을 도입해서 풀고자 하는 문제는 특정 부품의 내구 상태를 알아내는 것이다.
Output : 특정 부품의 크랙 사이즈

(참고) 자동차 도메인 지식 1
자동차는 내구 문제가 중요한 기계이다. 안전과도 연관이 있고, 사용 환경이 터프해서 문제가 발생할 여지가 많다. 그런데, 문제가 생기기 전까지 진단이 쉽지 않다. 분해를 해볼 수도 없고... 정비소에 가도 발견하기 어려운 문제들이 많다. 대부분의 소비자는 주로 소음으로 이상한 점이 관찰될 시에 문제를 인지하게 된다. 소음 + 기타 정보를 input 으로 차량의 문제를 찾아보자!
기반
자동차에서 정보를 수집하고, 관련 신호들을 처리 하는 시스템 우선적으로 필요하다. 이 시스템은 이미 구현이 되어 운영을 하고 있었다. N년동안 만들고 운영 중인 시스템이 있는데, 요약하자면 아래와 같다.
(자세한 내용은 https://nvds-manual.super.site/ 참조)
- 차량에 연결해서 Engine RPM, Motor RPM, Speed 외 기타 정보 수집
- 마이크 및 가속도계 연결해서 소음진동 신호 수집
- WIFI 로 Android/Windows 앱에 전달!
Android 태블릿 & 앱
- 데이터를 스트림으로 받아서 모니터링, 저장
- 저장한 데이터는 분석해서 차량을 진단!
데이터 수집 시스템은 이미 갖춰져 있고, 자동으로 분석 하는 프로그램도 사실 이미 다 구현이 되어있었다. 이 분석 프로그램은 고전(?)적인 신호 처리를 수행해서 차량 상태를 진단한다.
(참고) 자동차 도메인 지식 2
FFT 를 기반으로 RPM 과 연동해서 Order analysis 를 진행하는 데, 대충 요약하자면 지금 이 차량은 엔진이 진동이 크다, 타이어가 문제가 있다 뭐 이런 정보들을 주파수를 통해 알 수 있다.
딥러닝 모델 도입 이유
위에서 말한 기존의 방법으로는 풀 수 없었던 문제가 있었다. 특정 부품의 상태가 잘 판단이 안되더라. 자세히 말하기는 어렵지만 차량을 분해해야만 알 수 있는 특정 부품의 문제를 미리 알아내고 싶었다.
기존의 방법대로하면, 아래와 같은 소음진동 신호가
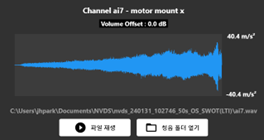
아래와 같은 에너지 레벨 (decibel), 에너지 레벨 그래프, 에너지 레벨 colormap 이 된다.
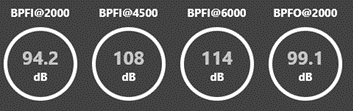
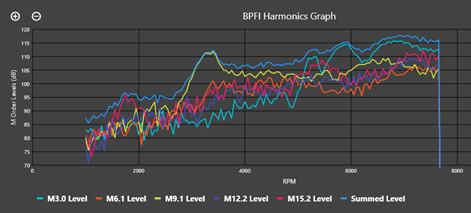
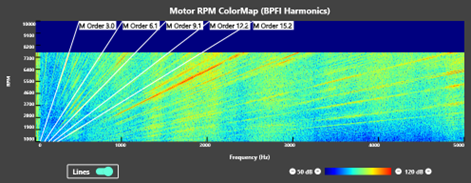
문제는 이 정보들을 기반으로 부품의 문제가 특정이 어렵다.
"요게 몇 데시벨이라서 높으니까 문제!" 이렇게 되어야 한다.
그런데!
하나 더 신기한 점은 colormap 을 이미지로 취급해서 눈으로 정상/이상 데이터를 꽤 많이 보다 보면 사람이 대략적으로 판단이 가능해진다는 점이다. 패턴이 보이게 된다.
데이터를 쏟아부어서 딥러닝 모델에게 패턴을 학습시키면 문제를 풀 수 있겠구나!
(참고) 자동차 도메인 지식 3
모든 차량은 공진 주파수 대역이 다 다르기 때문에, 에너지 레벨로 딱 구분하는 것이 어렵다. 다른 많은 진동 요소들이 더 있어서 더욱 어렵기도 하다. 그렇지만 패턴은 사람 눈과 뇌는 그 속에서 패턴을 끄집어 낼 수 있다는 점에 착안했다.
모델 선정 및 학습
Input Raw Data 와 이 데이터를 분석한 결과물이 있다. 분석 결과물은 1차원의 에너지 레벨, 2차원의 그래프, 3차원의 칼라맵인데, 다른 분야의 표현을 빌리자면, extracted feature 혹은 embedding vector라고 볼 수도 있겠다.
이러한 data 들을 기반으로 모델을 학습시켜서 만들어보자.
나에게는 차량에서 수집한 데이터와 학습을 위한 output value, "특정 부품의 크랙 사이즈"가 있다. 크랙 사이즈는 부품을 분해해서 알아낼 수 있다.
여러가지의 모델을 시험해 보았는데, 하나하나 해본 것들을 정리해보겠다.
첫 번째 시도 - 생성된 colormap 을 Input image 로 취급해서 CNN 기반 비전 딥러닝 모델을 도입
우선 성공? 했다.
모델은 MobileNet 을 transfer learning 해서 만들었다. 생성된 이미지가 색깔과 선들이 있기 때문에 imagenet 으로 pretrained 모델을 써도 충분할 것이라고 생각했다. 문제 난이도가 경량화 모델이어도 충분하며 android 태블릿 앱에 내장할 가능성이 있기 때문이다.
사실 모델 학습 과정에서는 다른 Net 들을 적용해보는 것은 어렵지 않기 때문에 다 해봤고, 큰 차이가 없는 데다가, 데이터 양이 부족해서 어떠한 net 을 하든 중요하지 않다.
데이터 양이 부족해서 transfer learning 이 아닌 바닥부터 학습 하는 것은 불가능하고, 할 필요도 없다. GPT4-V 나 기타 LLM 기반 멀티모달 모델은 비용과 데이터 보안 관련 문제로 고려하지 않았다.
도메인 지식이 필요한 내용 덧붙이자면, 사실 colormap 은 color 가 없다. 인위적으로 매칭 시켜준 것일 뿐. 흑백 모델이나 data 도 log scale 이 아니라 linear scale 로 바꿔서 학습을 다 시켜보고 싶은데, 사실 귀찮아서 안 해봤다.
두 번째 시도 - Input 을 Raw data 소리로 취급해서 음성 인식 관련 딥러닝 모델을 도입.
음성으로 취급 하는 것은 일단 불가 했다.
왜냐하면, 음성 인식 모델들이 긴 시간의 input 을 받기 어렵기 때문. 내 input data는 차량을 저속에서부터 고속까지 달리면서 수집했기 때문에 긴 시간 (약 1분) 이 필요하다. 쪼개서 넣을 수 있겠지만, 그렇다면 속도를 sweep 하면서 데이터를 받을 필요가 없지. 나중에 데이터가 정말 많으면 시도가 가능할 것 같다.
세 번째 시도 - 1차원 에너지 레벨을 이용해서 각종 machine learning 기반 regression 모델 도입
이것도 성공?했는데, 데이터가 쌓인다고 점점 더 잘 될 것 같지는 않다.
수많은 1차원 데시벨 값들이 기계/신호처리 이론에 기반하여 산출이 된다. 해당 정보들은 당연히 colormap 에 다 포함이 되어있다. 해당 값들을 기반으로 Linear Regression (Ridge, Lasso 도), random forest, decision tree, 등등 다 돌려봤다. 사실 요건 금방 바로바로 해볼 수 있는 것들이니.
워낙 가벼워서 모델은 다 만들어 봤고, Linear Regression, Ridge, Lasso 말고 나머지는 성능이 떨어져서 다 버렸다.
학습을 위해서 이것저것 hyper parameter 들을 적용 시켜 봤는데, 큰 직관을 가져다 주는 사항은 없었다. 그냥 다 돌려보고 좋은 것을 골랐다.
모델 배포 & 적용
Linear Regression 모델은 그냥 곱하고 더하면 끝이라서 Android/Windows 앱에 내장했다. 나중에 데이터가 늘어나서 학습을 다시 시키면, 계수들을 업데이트 해야 하니까 이것만 서버에서 가져오도록 준비했다.
문제는 CNN 기반 모델인데, 요것도 사실 모델 잘 말아서 앱으로 밀어 넣을 수 있긴 하다만, 서버에서 처리하도록 API 서버를 만들었다.
전체 구성은 다음과 같다.

서버는 Colormap 을 HTTP Post 로 이미지 스트림으로 받아서 CNN 모델을 돌리고 output 값을 return 해준다. 단순하게.
앱에서는 Linear Regression 이든 CNN 기반 Regression 이든 예상 결과를 바로바로 보여준다. 사용자는 차량에서 데이터를 취득하고 바로바로 결과를 볼 수 있다.
시스템 자체가 고객 (현대) 가 필요해서 만들었고, 지금은 여기에서만 사용되고, 나중에 아무리 많이 보급되어도 소비자가 많지는 않을 것이라 scalability 는 고려하지 않았다. (그냥 API 서버만 k8s 로 늘리면 되겟지.)
데이터 수집에 관한 고찰
이렇게 하나의 시스템을 바닥부터 끝까지 다 만들었는데, 포스트에 빠진 가장 중요한 내용이 하나 있다. 바로 데이터 수집 파이프라인이다.
결국 딥러닝 모델은 데이터의 양으로 승부를 봐야 하는 데, 이것이 문제다. 이번 task 는 연구를 위해 강제로 부품에 문제를 만들고 여러 샘플을 시험하면서 데이터를 확보했는데, 많이 부족하다. 실제 필드에 있는 많은 차량에서는 예상 결과가 틀릴 확률이 다분하고, 현재 학습된 데이터에 overfit 되어 있을 것으로 예상된다.
문제가 있는 차량에서 데이터를 수집해야 한다는 점, 학습을 위한 데이터는 차량을 분해해서 부품의 문제를 측정해야 한다는 점. 매우 매우 데이터를 수집하기 어려운 환경이다.
가장 좋은 시나리오는 정비소에 보급이 되고, 정비소에서 교체를 진행했을 시에 문제 부품을 받아서 데이터를 하나 씩 추가해 나가는 것이다. 교체를 하기 위해 측정된 raw data 는 중앙 서버에 모아야 하고.
애초에 본 시스템은 처음 고안 되었을 때부터 첫 번째 타겟 소비자가 정비소였고, 중앙 서버에 데이터를 업로드하도록 구상했으나, 현재는 중앙 서버가 없이 운영되고 있다. 데이터는 각자 태블릿/컴퓨터에 보관되는 중이다. 담당자 분들이 중앙 데이서 서버 구축을 시도 했으나, 조직의 여러 절차와 예산 등 복잡한 이해관계로 인해서 해결이 되지는 못했다.
이 문제가 자율주행처럼 어마무시한 가치를 가져다 준다면 모두가 적극적으로 했겠지. B2B 프로젝트 특성상 내가 어떻게 할 수 있는 것은 아니다.
소회
뭐 어쨌든, 처음부터 끝까지 딥러닝 기반 시스템을 만들고 배포했고 운영한다. 사용자가 많지는 않더라도. 딥러닝을 대학원생 때 처음 접하고, caffe 부터 고생하면서 설치하고, 강의도 하고, 자문도 하고, 개발도 하고, 많이 했는데, 딱 10년이 된 지금 처음으로 시스템을 구축했다. 전체 시스템의 부분적으로만 참여하다가, 하드웨어부터 펌웨어, 프론트엔드, 백엔드, 딥러닝 모델까지 다 만들 수 있게 되니까 혼자서 다 해내니 뿌듯하다.
요즘 핫한 generative ai 는 아니지만, 곧 generative ai 를 기반으로 시스템을 만들 기회가 생길 것 같다.